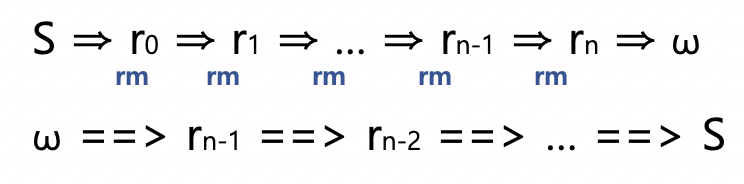우선, 알고있어야할 한가지는 LR parser는 bottom-up parsing의 방식을 사용하며, 그 과정은 right-most derivation(우측 우선 유도) 과정의 역순을 따른다는 것입니다.
이는 유도과정의 역순으로 되돌려, 현재 결과로부터 초기 symbol을 얻어내는 방식입니다.
이 경우 사람이 parsing table을 구현하는 것은 매우 어렵고 복잡해지므로, 프로그램이 이를 대신 해주게 됩니다.
따라서 이번 시간에는 parsing table의 구현 없이, 이미 주어진 parsing table이 있을 때 어떻게 parsing이 이루어지는 지 예제를 통해 살펴 보게 될 것입니다.
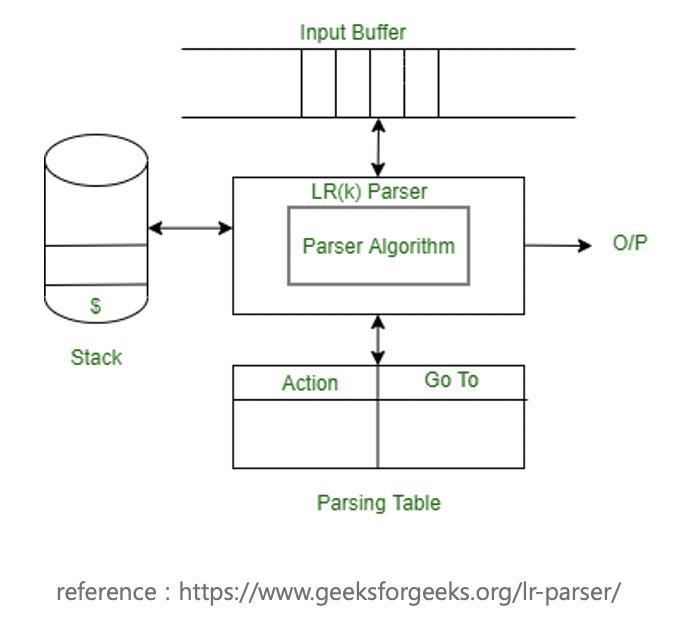
참고로, LR parsing table의 구조는 아래와 같이 ACTION table과 GOTO table이 합쳐진 형태로 구성되었으며, LL에서와 마찬가지로 stack과 input buffer를 사용하여 parsing을 수행합니다. 그럼 전반적으로 LR parser 프로그램이 작동하는 구조가 다음과 같이 됩니다.
LR parser 프로그램의 작동 구조
먼저 LR parser에 주어진 parsing action은 다음과 같다는 걸 다시 복습하고 갑시다.
shift : input symbol을 스택에 push (그 위에 상태 n을 저장)
accept : parsing 끝남
error : syntax에 오류
reduce : handle을 non-terminal로 치환.
LR parsing table을 이용한 parsing 예제
input 프로그램으로 a, a 를 넣었을 경우 (input = a, a$)의 예시를 살펴봅니다.
주어진 예제는, Grammer rule과 파싱 테이블, 시작상태 Stack : 0 과 input : a, a$ 만 써놓고 직접 다시 풀어볼 수 있습니다.
acc ex. [STACK] 0 LIST 1, [INPUT] $일때 M[1, $]에 acc 있음. 끝낸다는뜻이므로 parsing 종료
마찬가지로 Stack의 top은 문자열의 앞부분에 있다는 점을 주의하며, 위와 같이 parsing을 수행하시면 됩니다.
아래는 직접 예제의 시작상태부터 3번째 상태까지 풀어본 내용입니다. 참고바랍니다.
0이 시작 상태.
스택의 top에 있는 상태(state)와 입력 기호를 가지고 action 테이블을 찾아간다.
stack의 top 0(state), a(입력) 가지고 테이블 찾아감 → s3 나옴. (= 3번 규칙을 가지고 shift 해라) a를 shift함 (stack에 푸시해줌) + stack의 top에 3번 써줌 → 끝난 stack 상태 : 0 ➡️ 0 a 3
stack의 top 3(state), “,” (입력) 가지고 테이블 찾아감 → r3 나옴. (= 3번 규칙을 가지고 reduce 해라) a를 ELEMENT라는 symbol로 reduce 해야함 현재 stack : 0 a 3 — 여기에서 상태번호 포함해서 a를 pop 해서 없앤다 (”a 3”을 pop) — a가 있던 자리를 Element로 바꾼다 — stack 상태는 0 Element 인데, 이때 0과 Element를 가지고 GOTO 테이블 찾아간다. → 2 나옴 → 2를 push → 끝난 stack 상태 : 0 a 3 ➡️ 0 Element 2
stack의 top 2(state), “,”(입력) 가지고 테이블 찾아감 → r2 나옴. (= 2번 규칙을 가지고 reduce 해라) Element를 List라는 symbol로 reduce 해야함 현재 stack : 0 Element 2 — 여기에서 상태번호 포함해서 Element를 pop 해서 없앤다 (”Element 2”을 pop) — Element가 있던 자리를 List로 바꾼다 — stack 상태는 0 LIST 인데, 이때 0과 LIST를 가지고 GOTO 테이블 찾아간다. → 1 나옴 → 1를 push → 끝난 stack 상태 : 0 Element 2 ➡️ 0 LIST 1
… 다적기에너무많으니더이상의내용은생략합니다. 알아서풀어보도록 합시다.
자 이렇게 LR parsing table을 이용해 parsing하는 예제를 풀어보았습니다.
이를 어떤 초기 상태(대문자)에서 말단 상태(소문자)로 확장시켜야합니다. 그게 아래 주어진 LL 파서의 역할입니다.
이 예시와 같이, 보통 그 문법 규칙의 번호가 표의 칸(entry)에 주어집니다.
parsing table이 주어졌을 때, 이를 이용해 LL parsing 하는 과정
이제 parsing 방법을 설명해볼까요.
stack에 non-terminal이 들어가고 terminal이 input으로 주어집니다. non-terminal과 input을 앞에서부터 읽어가면서, 이 두개가 주어졌을 때의 규칙을 parsing table에서 찾아 수행하는 게 기본입니다.
여기서 먼저 한가지 주의해야 할 점은 $가 있는 쪽이 EOF(stack의 바닥)이라는 점입니다.
여기서 stack은 거꾸로 되있어 맨 앞에 $가 붙어 있다고 보면 됩니다. (= stack의 top(맨위)는 맨 뒤의 문자)
파싱 테이블을 보고 LL(1) parsing 하는 방법은 다음과 같이 소개 되어있습니다.
(X는 stack의 top에 있는 symbol, a는 현재 input symbol을 의미)
X = a = $이면 종료 (accept)
X = a이면 stack에 있는 X(=a)와 읽는 중인 input의 맨 앞에 있는 a 동시에 Pop 해서 버림
X가 non-terminal일 경우 표를 찾아봐서 X (nontermial) → a(terminal)로 변하는 규칙 있으면 거기 있는 규칙번호를 사용 (= M[X,a]에 있는 규칙 사용) → 그 규칙번호에 있는 문법의 결과(유도)로 X 치환
위의 어느 규칙도 만족하지 않고, 표 찾아봤는데 찾은 칸이 비어있으면 error
말은 쉽지만 잘 이해가 가지 않죠?
먼저 예제를 보면서 같이 풀어보면 이해가 될 거에요.
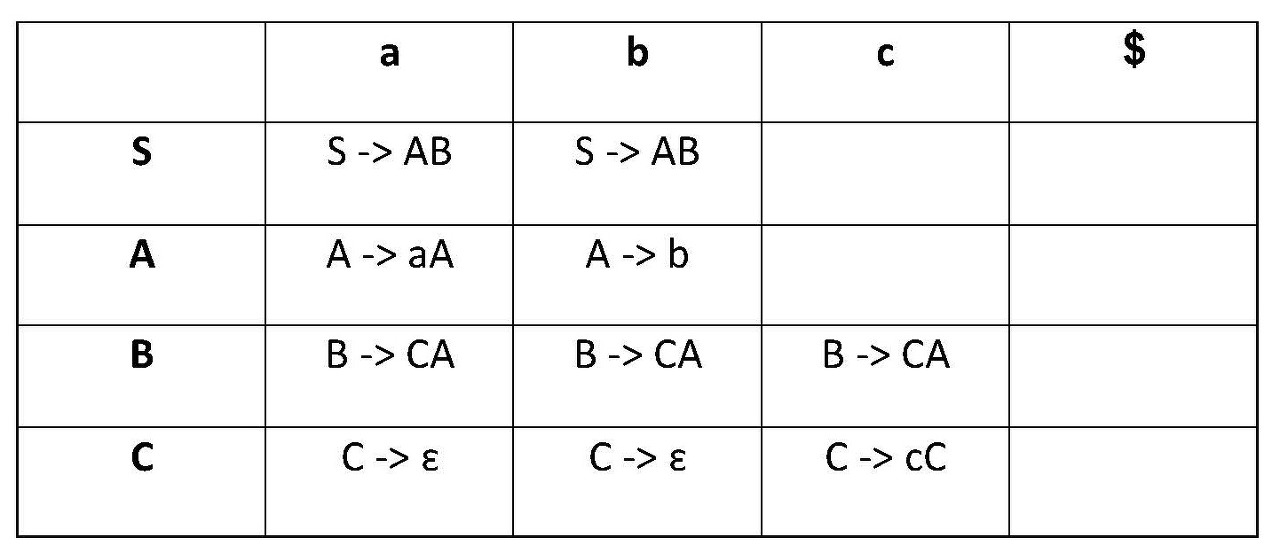
순서대로 Stack, input, Actions일 때 시작상태라고 합시다.
1. stack에 있는 것은 $S , input은 aabbb$ 일텐데 여기서 stack의 top(맨 앞)이 S, input의 맨 앞이 a입니다.
이때 S와 a가 만나는 표를 보니 1이 써져있군요. 그러면 Stack의 top 있는 S에다가 규칙 1을 적용해줍니다.
S였던 문자열을 규칙 1에 맞게 aSb로 치환해주었어요.
그럼 [stack] $S, [input]aabbbb$인 상태에서, [stack] $bSa , [input]aabbbb$ 인 상태로 변했죠.
2. 이어서 해볼까요. [stack] $S, [input]aabbbb$인 상태에서, [stack] $bSa , [input]aabbbb$ 인 상태에서 또 시작해봅니다.
stack의 top은 a, input의 맨 앞은 a네요. 같은 값이 나왔으므로 두 값 모두 pop 해서 버립니다.
이제 상태가 [stack] $bS , [input]abbbb$ 가 되었어요.
... 이런 식으로 쭉 진행을 하게 되는 거에요.
3. 마지막에 아무 값도 안 남고 stack과 input 모두 $ 만 남아 비어있게 된 상태가 되면 parsing을 종료합니다.
예제 2 : Parsing table 구현하기
Parsing table을 구현한다는 것은, non-terminal X 상태일 때 input의 맨 앞에 terminal a가 주어질 경우 적용할 규칙을 정한다는 것입니다. 그리고 그 규칙은 표의 M[X, a] 위치에 적어줍니다.
따라서, parsing table을 구현하기 위해서는 FIRST와 FOLLOW 알고리즘이 필요합니다.
input의 맨 앞에 주어진 non-terminal a를 찾아야하기 때문에 FIRST 알고리즘이 필요한 것입니다. 그리고 이 non-terminal이 다른 문자열(terminal)을 생성하지 못하고 사라지는 경우(= A→ε 인 경우)에, 그 뒤에 올 다음 terminal을 찾아와야하기 때문에 FOLLOW 알고리즘이 필요하다고 이해하면 됩니다.
FIRST(X)와 FOLLOW(X) 알고리즘 이해하기 (예제)
문법 규칙을 풀이하면 FOLLOW(X), FIRST(X)를 손쉽게 구할 수 있습니다.
FIRST(X) 알고리즘 예제
다음은 그 예제입니다.
첫번째로 FIRST 알고리즘 예제를 살펴봅니다.
FIRST(X)를 구하려면 우변에 non-terminal X를 갖는 규칙들을 먼저 보아야합니다.
시험삼아 예제 2의 FIRST(E)를 구해볼까요?
FIRST(E)를 구하자는 것은 즉, non-terminal E가 유도한 최종 문자열(=terminal)의 앞 문자를 구하자는 것입니다.
좌변에 E를 가지는 식을 보니 1번 규칙인 E -> TE'가 보입니다. E를 유도했을 때 앞에 T라는 non-terminal이 유도되어나오는 모양인데요.
그러면 E가 유도한 terminal의 앞글자는 곧 T가 유도한 terminal의 앞 문자겠군요. 그러면 또 T를 좌변에 갖는 규칙을 볼까요.
이제 3번 규칙인 T->FT'가 보입니다. 이제 T가 유도한 terminal의 맨 앞 문자는 곧 F가 유도한 terminal의 맨 앞 문자라는 걸 알게되죠.
이제까지 FIRST(E)=FIRST(T)=FIRST(F)인 셈입니다.
F를 좌변에 가지는 규칙을 보니, F -> (E) | id가 있습니다. F는 (E)와 id를 유도한다는 것이죠. F가 유도하는 terminal의 맨 앞 문자는 "(" 또는 id 입니다. 그러면 FIRST(F) = {(, id}라고 적을 수 있습니다.
FOLLOW(X) 알고리즘 예제
그 다음으로 FOLLOW 알고리즘 예제를 살펴봅니다.
FOLLOW(X)를 구하려면 우변에 non-terminal X를 갖는 규칙들을 먼저 보아야합니다.
시험삼아 FOLLOW(F)를 구해볼까요?
FOLLOW(F)를 구하자는 것은 즉, non-terminal F의 바로 다음에 올 문자를 구하는 것입니다.
우변에 F를 가지는 식을 보니 3번 규칙인 T-> FT'와 4번 규칙인 T'->*FT'가 보입니다. 이럴 경우는 어떻게 FOLLOW(F)를 구할까요?
먼저 확실한 것은, F 다음에 무조건 non-terminal T'가 나오네요. 이럴 경우 F의 바로 다음에 올 문자에는 T'의 맨 앞 문자도 포함되겠죠?
그러니 FOLLOW(F)에는 FIRST(T')를 먼저 포함시켜줍니다.
그런데 이때 만일 T'가 ε이 되어버리는 경우는요? 그럼 F 바로 다음엔 뭐가 올까요?
예를 들어 현재까지 문자열이 Tabc이고 T를 FT'로 유도하여 FT'abc가 되었다고 해봅시다.
이때 T'가 ε이 되어 사라지면 Fabc가 됩니다. 그러면 이 F 바로 뒤의 a 부분은 어떻게 찾아야 나올까요? 예, 바로 FOLLOW(T)입니다. 처음의 Tabc 상태에서 그 뒤에 있던게 abc니까요. 그러면 FOLLOW(F)에는 FOLLOW(T)도 포함되게 됩니다.
이때, FOLLOW(F)의 결과에서는 ε를 제외해야합니다.
이유 : 기본적으로 FOLLOW의 결과는 절대 ε(공집합)이 포함될 수 없습니다. 왜냐하면 문자열의 끝인 EOF가 항상 $이므로 ε 대신 최소한 $이 들어가게 되기 때문이죠.
결론적으로, FOLLOW(X)는 A->XB일 때 FIRST(B) + FOLLOW(A) - {ε}로 계산할 수 있습니다.
만일 A->X일 경우 FOLLOW(X) - {ε}이겠지만요.
A → XB 일때, FOLLOW(X) = FIRST(B) + FOLLOW(A) - {ε}
A → X 일때, FOLLOW(X) = FOLLOW(A) - {ε}
FOLLOW(X)와 FIRST(X) 이용해서 Parsing table 채우기
비어있는 표와, FIRST(X), FOLLOW(X) 그리고 X에 관한 문법 번호만 있으면 parsing table을 만들 수 있습니다.
Parsing table 채우기 예제
간단하게 규칙을 제시하면 다음과 같습니다.
NonTerminal A,B,C가 nullable이 아니라면, First(A,B,C)를 기록한다. NonTermianl A,B,C가 nullable이라면, Follow(A,B,C)를 기록한다.
FIRST(X)는 X를 terminal로 유도했을 때 맨 앞에 나오는 terminal.
FOLLOW(X)는 A→XB일 때 : FOLLOW(A) + FIRST(B) - {ε}임
주의) X가 start symbol일 경우 $ 추가하기!!
정리
A는 non-terminal이고, FIRST(A) 또는 FOLLOW(A)는 non-terminal이다.
M[A, FIRST(A)]에 'A → (해당 FIRST(A)를 유도한 규칙)'의 규칙 번호를 적어준다.
FIRST(A)에서 ε인 경우에만, M[A, FOLLOW(A)]에 A → ε 의 규칙 번호를 적어준다.
무작정 표를 채우려면 어려워보이지만, 정리하자면 위와 같은 과정을 따라 문제를 풀 수 있습니다.
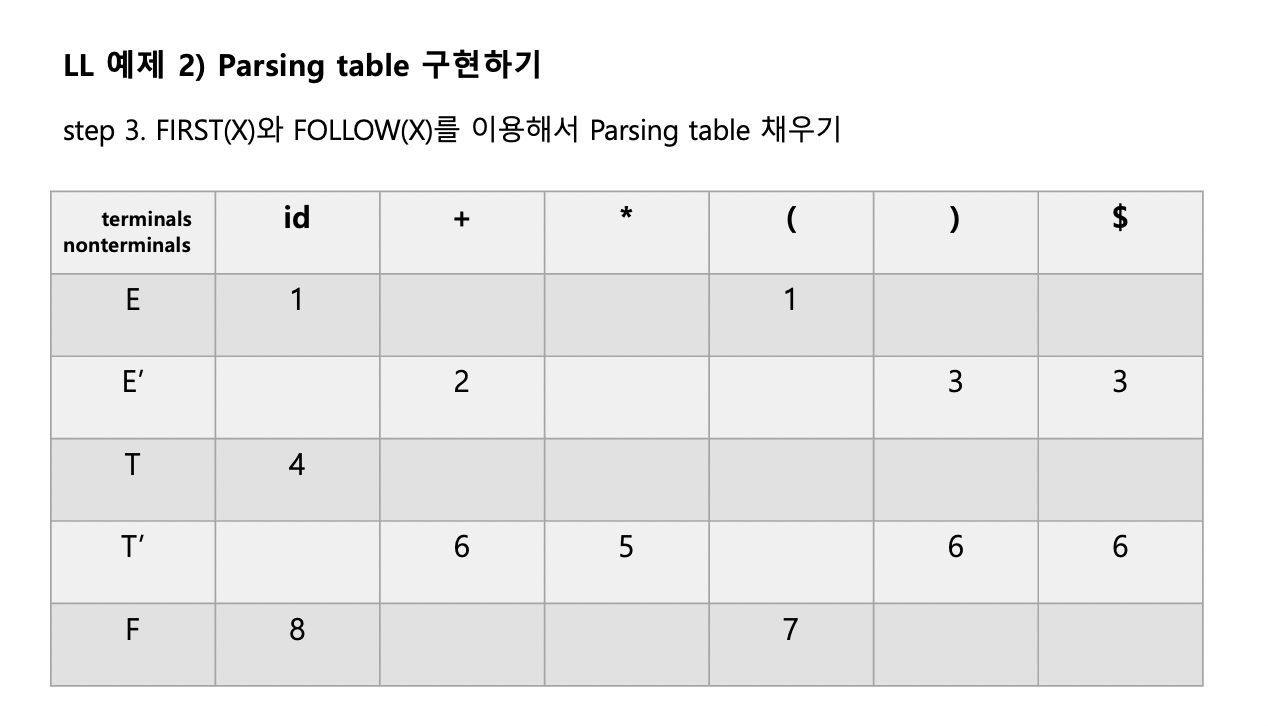
위에 나온 표를 비워놓은 빈 표를 준비합시다. 이제 제 설명을 따라가며 표의 칸에다 번호를 적어봅시다.
한번, non-terminal E'의 줄에 있는 칸들을 채워볼까요?
우선 FIRST(E')가 뭔 지 먼저 알아봅시다. FIRST(E') = {+,ε }이 나오네요.
이제 M[E, FIRST(E')]의 자리에 규칙번호를 채워야해요.
그러니 M[E',+]의 자리에는 +가 맨 앞에 나오는 규칙인 E'->+TE'의 규칙번호 2를 적어줍니다.
이제 M[E', ε]를 채우려 하니...ε 는 non-terminal에 없죠. 그러면 어디에다가 어떤 규칙을 써야할까요?
이때는 M[E', FOLLOW(E')]의 자리에 E'에서 ε 를 유도하는 규칙의 규칙번호를 대신 써주면 된답니다.
보니까 3번 규칙이 E'->ε 로 ε 를 유도하네요. FOLLOW(E')는 {), $}이니, M[E', )]와 M[E',$]의 자리에 그 규칙번호인 3을 써줍니다.
이 과정을 반복하면 LL 파싱 테이블을 어렵지 않게 구현할 수 있습니다.
예제 3 : 이 문법은 예측 parsing이 가능한가? (LL condition)
LL 파서의 모든 경우에서 deterministic parsing, 즉 예측 parsing이 가능한 것은 아닙니다.
앞서 보여드린 parsing table의 각 칸에 쓰인 규칙 번호가 한 개가 아니라면 어떻게 될까요? 표의 칸 하나에 번호 여러 개가 쓰여있을 경우 말이에요.
이 경우 한 규칙을 사용해보고, 그게 안되면 다시 돌아나와서 다른 것을 선택하는 backtracking이 일어나게 됩니다. 이런 경우를 non-deterministic LL parser라고 부르지요.
예측 parsing이 가능하다는 것, 즉 detereministic parser라는 것은 파싱 테이블에서 각 칸이 겹치지 않고 하나의 규칙만 가지게 되는 경우와 같습니다.
그러한 예측 parsing의 조건은 다음과 같습니다.
A → a | ß 일 때
FIRST(a)와 FIRST(ß) 겹치지 않아야한다.
a가 ε 유도하는 경우, FOLLOW(a)와 FIRST(ß)가 겹치지 않아야한다.
한번 이해를 해볼까요.
LL condition을 "파싱 테이블의 규칙이 한 칸 당 하나씩 있을 경우의 조건"으로 바라보면 쉽게 이해할 수 있습니다.
첫번째 조건에서, FIRST(a)와 FIRST(ß)가 겹치면 유도결과가 둘다 똑같은 문자로 시작하는 것이겠죠. 이러면 테이블 구현 시 M[A,FIRST(A)]를 작성할 때 적을 칸이 겹치겠네요. 서로 다른 terminal을 유도하니 다른 규칙번호를 쓰는데, 칸이 겹치니 여러 개 규칙번호가 한 칸에 들어갈 수 밖에 없는 상황이 벌어질 거에요.
두번째 조건에서는, a가 ε되면 그 바로 뒤에 FOLLOW(A)의 terminal들이 나오게 되겠죠.
이때 FIRST(B)가 FOLLOW(B)와 같은 경우를 예를 들어볼까요. A123의 상태에서 유도규칙을 적용하여 a123과 ß123으로 만들었다고 해봅시다 이때 a가 ε이 되어 사라지고 ß가 FOLLOW(A)와 같은 1으로 시작할 경우 두가지를 모두 볼 거에요. 앞선 경우는 123, 뒤의 경우는 1(~~)123라는 문자열이 만들어집니다. 이때, 완성된 파싱테이블으로 파싱할 때 M[A, 1]을 찾는 경우 앞의 결과물과 뒤의 결과물의 규칙 칸이 또 겹칠 수 있습니다. 저는 이렇게 첫번째 조건과 두번째 조건을 이해했습니다.
이제 예제를 통해, 다음 문법 규칙은 LL condition을 만족하는 지 아닌 지 한번 풀어봅시다.
LL(1) condition의 예제
G1의 경우 먼저 볼까요.
FIRST(S)인 iCtSS’와 a가 서로 겹치는 가? → X → 1번째 조건 만족
둘 중 어느 것도 우변이 ε 생성하지 않음 → 2번째 조건 만족
그럼 이제 G2의 경우를 봅니다.
S’의 우변에 ε 있음 (2번째 조건 봐야함)
ε 생성하는 문법 이외에 다른 문법은 S’ → eS
FIRST(eS) = e
FOLLOW(S’)와 FIRST(eS)가 겹치는가? → FOLLOW(S’)에 e 있으므로 겹침
→ 2번째 조건 만족하지 않는다!
⇒ LL(1) 조건을 만족하지 않음!
이런 방식으로 LL 조건을 만족하는 지 아닌 지 검사해볼 수 있습니다.
컴파일러 과목을 공부할 때 제게 특히 어려웠던 부분이 이 부분인데요. 이 부분에 대한 설명 자료가 얼마 없기도 하고 해서 누군가에게 도움이 될까 싶어 만들어본 포스팅입니다. 쉽게 풀어 설명하는 것을 목표로 노력했네요.
제가 이번에 학교에서 수강한 컴파일러 과목의 기말고사 시험이 끝난 지 이틀이 지났네요.. 시간을 많이 들여 강의노트를 정리한 페이지를 만들고, 거의 통째로 외우다시피 시험 준비를 했어요.
그렇지만 불행하게도 강의노트에 잘 적혀있지 않은 부분들에서 기말 고사 문제가 많이 나와서 슬펐습니다. (ㅠㅠ)
제가 강의노트의 어려운 예제들을 풀고 이해하는 데 들었던 시간이 상당했었거든요. 인터넷에도 친절히 설명하는 자료가 거의 없었어서 더욱 그랬죠. 그래서 "예제를 이해하고 공부한 내 노력이 아까우니, 따로 예제들을 쉽게 풀이하는 포스팅을 만들어보자!"는 생각이 들었습니다.
아무래도 과목 진도 상 중후반쯤에 위치한 내용에다가 그 분량이 많아요. 그러니 컴파일러 과목의 앞부분에 대한 기초 설명은 다소 생략할 수 있습니다. 사전 지식이 어느정도 있다는 가정 하에 설명할 예정입니다.
그럼 시작합니다. ^^
예제 문제를 풀기 전 개념 빌드업 포스팅으로 시작합니다.
컴파일러와 parser?
우선 컴파일러가 무엇인지부터 간단히 설명하겠습니다. 컴파일러는 우리가 흔히 아는 컴파일러 그대로입니다.
즉, 코드를 실행시킨 뒤, 그 실행 결과를 돌려주는 프로그램입니다.
기본적으로 컴파일러 과정은 lexer -> parser -> type-checker -> interpreter의 과정으로 이루어지게 됩니다.
lexer는 토큰이라는 단위로 코드의 문법 오류를 검출하는 역할을 합니다.
예를 들어, i + 2 = 3 이라는 문장이 있다고 해봅시다.
이때, 매 문장 끝에 ;(semicolon)라는 토큰을 붙여야한다는 문법 규칙이 있을 경우, ";" 라는 토큰을 붙이지 않은 이 구문을 문법 오류로 처리해준다는 뜻입니다.
parser는 프로그래밍 코드를 입력 받은 뒤, 그걸 프로그램이 해석할 수 있는 단위로 쪼개 그 문장을 구조를 알아내는 구문 분석 작업을 해주는 프로그램입니다.
i = i + 1 이걸 int i (int 변수), = (할당 연산자), i(int 변수), +(수학 연산자),1(1이라는 정수형 숫자) 이런 식으로 구조를 쪼개 준다는 것이죠.
type checker는 주어진 구문에 타입 오류가 없는 지 검사합니다. 만약 float i; 로 앞서 선언한 변수에, 타입캐스팅 연산자 등이 없이 바로 i = 'a' 라는 식으로 char 값이 들어간다면? float 변수에 char 값을 담으려는 충돌이 일어나므로 타입 오류로 분류해야겠습니다.
interpreter는 앞선 과정을 통해 코드를 검사해봤을 때 아무 문제가 없는 경우 최종적으로 실행되는 데요.
이 코드를 실행해 나오는 결과를 보여줍니다.
컴파일러 실행 하는 중에, 입력된 코드의 오류를 발견하게 되면 어떻게 될까요?
그 과정에서 나오는 모든 오류를 보여준 후 다음 과정으로 넘어가지 않고 종료됩니다.
Parser의 원리
우선, 프로그래밍 언어를 유도하는 과정에 대해 먼저 설명해볼까요.
프로그래밍 언어, 즉 코드는, 쉽게 말하면, 어떤 규칙에 따라 문자열을 확장한 것에 불과하다고 볼 수 있습니다.
저기 트리 루트에 있는 expr 보이시나요? 우리가 expr이라는 것만 갖고 있는 상태라고 해봅시다.
그리고 우리는 다음 epxr 과 연산자, term이 필요하다는 규칙도 가지고 있다고 해봅시다.
그럼 저런 방식으로 expr을 expr + term이라는 문자열로 확장시킬 수 있는 거에요. 다양한 문법 규칙을 통해 문자열을 확장하면, 저 코드가 아니더라도 우리가 원하는 문법 구조 안의 모든 프로그래밍 코드를 표현할 수 있습니다.
program이라는 토큰 하나에서 시작해서 int main() {int i; i = 0; i = i + 1; }이런 식으로 얼마든지 확장이 가능해지거든요.
이렇게 문법 규칙에 따라 문자열을 유도하는 과정을 거꾸로 생각하면, 파싱이 가능합니다.
주어진 문법규칙을 통해, 이 코드가 문법 규칙에 맞는 지 체크하고 코드를 parsing 할 수 있거든요.
만일 어떤 변수가 나왔고 그 다음에 "="라는 연산자가 나왔다. 그러면 그 우변에 무조건 숫자 혹은 숫자를 사칙연산한 식이 나와야한다는 규칙이 있다고 가정합시다. 그러면 문법 규칙은 "변수 = 식", "식 = 숫자를 사칙연산한 식 또는 그냥 숫자" 이렇게 나타낼 수 있겠죠.
이런 상황에서, 입력으로 변수 i = 'c' + 9라는 문장이 들어와 이걸 파싱한다고 합시다.
이 규칙에 따르려면 변수(=i), 할당연산자("=") 뒤에 나오는 건 반드시 숫자계산식이여야 해요. 그런데 그 뒤의 'c'+9라는 식은 숫자로만 사칙연산된 식도 아니고 숫자 그 자체인 것도 아니죠. 이때 이걸 발견해서 parsing 에러를 내게 되는 거에요.
파서 입장에서는 "변수랑 "=" 라는 연산자를 읽었으니, 변수 = 숫자식 으로 해석해야한다! 그러니 뒤에 숫자식이 나오는 지 체크해보자!"하고 체크해보니 아니라 이거죠.
만일 i = 1 + 1 과 같이 앞선 문법 규칙을 만족하는 식이면 parsing 에러 없이 돌아가는 것이구요.
다양한 구조의 parse tree
parsing 에러 없이 파서가 잘 돌아가면 어떻게 될까요?
오류 없이 잘 parsing 이 끝나면, parser tree를 결과물로 만들게 됩니다. 문장구조를 분석한 그 요소들을 이렇게 배치해 일종의 tree 모양으로 확장 시키는 모습이죠.
파서를 설명할 때 non-terminal과 terminal에 대한 설명이 계속 나오게 되는데요. 이걸 확실하게 짚고 넘어갑시다.
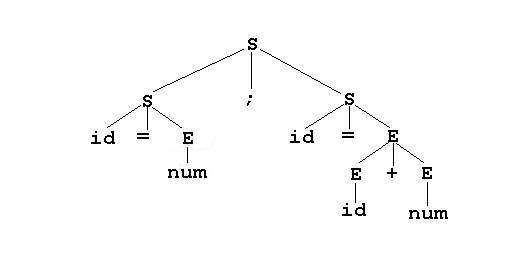
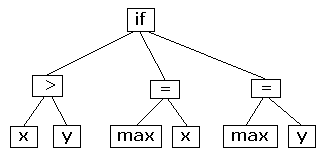
여기에서 첫번째 트리를 봅시다.
여기서 최종상태 (말단노드)인 id, =, num 등을 terminal 문자, 최종상태가 아닌 S, E 등을 non-terminal이라고 할거에요.
이 부분은 parsing 테이블을 볼 때 계속해서 언급이 나오니, 헷갈리지 않게 꼭 기억해두어야합니다. non-terminal이 확장되면 최종상태인 terminal로 변하는 것이므로, non-terminal -> terminal의 구조라고 생각해두시면 좋아요.
Parser의 종류
앞서 parser는 프로그램코드를 특정한 의미를 가진 구문으로 쪼갠다고 말씀드렸습니다.
그러한 parser에도 LL 파서(top-down parser)와 LR 파서(bottom-up parser)의 2가지 종류가 있는데요.
초기상태에서 말단 요소로 확장하는 방식이 LL 파서에 똑같이 적용됩니다. 그래서 top-down이라고 부르게 되지요.
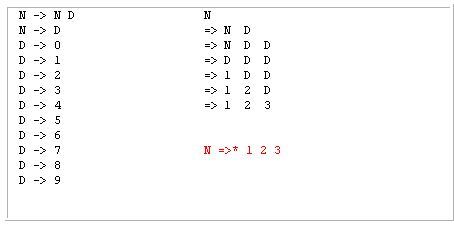
LL 파서는 이렇게 쪼개기 위해서 Left-most derivation 순으로 분석합니다. 왼쪽에다가 문자를 새로 붙여가면서 확장하는 거에요.
Left-most derivation 예시
다음과 같이 왼쪽부터 그 요소가 추가되거나 바뀌고 있죠. 왼쪽부터 유도한다하여 left-most derivation입니다.
LL 파서도 그 종류가 2가지로 나뉘는데요, deterministic과 non-deterministic입니다. non-deterministic은 predictive(예측 가능) parser라고도 불려요.
어떤 상태(non-termial=최종상태가 아닌 것)가 주어졌을 때, 이를 최종 상태(=입력값=terminal)로 확장시키는 데 사용할 수 있는 규칙이 여러 개냐 아니냐로 구분됩니다.
LL 파서는 문법 규칙과 그 언어의 정규식을 통해 만들어진 parsing table을 사용하여 parsing 합니다.
아래의 표는 LL(1)의 parsing table이라고 볼 수 있습니다. 각 칸에 문법 규칙이 하나씩 들어있으니까 LL 파서 중 predictive parser라고 볼 수 있겠네요. 만일 어떤 non-terminal과 termianal에 대해 확장 규칙이 여러 개면 여러 가지의 경우가 발생할 수 있으므로 backtracking이 일어나게 된다고 합니다.
이 parsing table은 "현재 상태는 S인 non-terminal인데, 현재 읽은 Input 값이 a라면? S->AB라는 규칙을 적용하세요~" 라는 의미를 담고 있는 parsing table이랍니다. 자세한 것은 예제 풀이 포스팅에서 보게 될 거에요.
LL(1) predictive parser
LR 파서
LR 파서는 마찬가지로 parsing 테이블을 만들지만, right-most derivation의 역순으로 파싱을 수행합니다.
문자열을 확장시키는 유도과정을 뒤짚어 점점 초기상태로 돌리는 방향으로 Parsing을 하는 것이죠.
그래서 트리의 말단에서 위로 올라가는 방향으로 보여 bottom-up parsing이라고도 부릅니다.
LR parsing table은 ACTION 테이블과 GOTO 테이블이 합쳐진 형태에요.
먼저, Action 테이블에서는 어떤 상태(states)에서 입력값(terminals) 받았을 때 무슨 action을 취하는 지 알려줍니다.
그리고 Goto 테이블에서는 어떤 상태(states)에서 입력값이 아닌 상태(Non-terminals) 받았을 때 다음 상태를 알려주지요.
LR 파서의 기본 동작들(actions)는 다음과 같아요. shift, reduce, accept, error의 4가지 입니다.
그 기본 동작들의 의미는 다음과 같으며, 이들을 활용해 최종상태(input)에서 초기 상태로 쭉쭉 돌릴 수 있게 되는 것입니다.