분류 전체보기
-
[Libft] C 언어 라이브러리 구현_Part2_추가함수 구현12021.05.23
-
[Libft] C 언어 라이브러리 구현_Part1_malloc을 사용한 함수2021.05.20
-
[Libft] C 언어 라이브러리 구현_Part1_문자 판별 + 변환 관련 함수2021.05.20
-
[Libft] C 언어 라이브러리 구현_Part1_문자열 관련 함수2021.05.20
-
[Libft] C 언어 라이브러리 구현_Part1_mem관련 함수2021.05.17
[Libft] C 언어 라이브러리 구현_Part2_추가함수 구현1
혹시나 문제가 된다면 바로 비공개 처리하겠습니다. 지적이나 댓글 환영합니다!
이번 포스팅에서는 문자열 관련 함수들을 구현해보겠다.
소개할 함수 3개의 공통점은 모두 동적할당(malloc)을 사용하여 편집된 문자열을 새로 만드는 것이다.
이번 함수들은 메뉴얼이 이미 과제 페이지에 영어로 상세히 적혀있는 대신, 전보다 구현이 복잡한 특징을 가졌다.
따라서 이번 시간에는 함수의 역할 대한 정리보다는 함수를 어떤 방식으로 구현했는지, 구현에서 어떤 문제들을 마주쳤고 이를 어떻게 해결했는 지 위주로 설명하겠다. (면접용 연습)
주의사항이라고 적은 사항들이 대부분 내가 실수했으나 고쳐서 어떻게 해결했는 지에 대한 내용들이다.
참고로, 내가 정의한 libft.h 헤더에는 <unistd.h>와 <stdlib.h>가 include 되어있다. 따라서 libft.h를 호출하면, 따로 정의하지 않고도 <unistd.h> 에 정의된 size_t 타입과 <stdlib.h>의 malloc/free를 사용할 수 있다.
(1) ft_substr : 부분문자열 생성
: 주어진 시작 지점에서 주어진 길이만큼 원본 문자열을 잘라, 부분문자열을 생성한다.
- 구현 코드 예시 :
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
#include "libft.h"
char *ft_substr(char const *s, unsigned int start, size_t len)
{
char *sub;
size_t i;
size_t size;
i = 0;
size = ft_strlen(s);
if (start >= size)
{
if (!(sub = malloc(sizeof(char))))
return (0);
}
else
{
if (size - start < len)
len = size - start;
if (!(sub = malloc(sizeof(char) * (len + 1))))
return (0);
while (i < len && s[start + i])
{
sub[i] = s[start + i];
i++;
}
}
sub[i] = '\0';
return (sub);
}
|
cs |
- 예외처리 : 부분문자열을 생성할 시작지점이 문자열의 길이보다 같거나 크다면, 부분문자열을 생성할 수 없다. 따라서 이 경우에는 크기를 1만큼 동적할당 해준 뒤 그 공간에 '\0'을 넣은 후 포인터를 리턴하게 만들었다. (free할 수 있도록, 동적할당된 메모리를 리턴)
- 예외처리 : 널가드
동적할당이 실패할 경우(커널의 메모리 공간 부족 등의 여러 이유로) 0을 리턴한다.
ex) if (!(sub)) return (0);
=> 동적할당이 실패한 경우는 sub가 null(=0 =false)이 된다. 이때 !(sub)의 값은 true로, if 조건문의 코드를 실행시킨다.
- 주의할 점 : 매개변수로 받은 len이, 처리될 수 있는 최대 길이(strlen(s) - start)보다 길 경우를 예외처리 해주어야 한다. 내 친구는 이 부분을 예외처리 하지 않았다가 동료평가에서 0점을 받았다. 예를 들어, 문자열이 "abcd", start 지점이 1으로 주어졌는데, len 에서는 10000이 주어져, 실제로 문자열을 복사 가능한 메모리 3칸이 아닌 10000개의 메모리를 할당하는 상황을 가정하자. 이런 경우 매우 비효율적이고 불필요하게 메모리를 많이 차지한다. 따라서 시작점으로부터 끝까지의 문자열의 길이가 주어진 len 보다 짧을 경우, len 대신 그 길이만큼만 메모리를 할당하게 끔 코드를 수정하였다.
- 반복문을 사용하여, 원본문자열의 start 지점부터 최대 len만큼의 문자들이, 동적할당된 메모리에 복사될 수 있도록 하였다.
- 부분문자열의 복사가 끝난 후에, 포인터의 끝에 null을 넣어 리턴하였다.
(2) ft_strjoin : 2개의 문자열을 병합
: malloc으로 동적할당하여, 문자열 2개를 나란히 합친 새로운 문자열을 생성한다.
- 구현 코드 예시 :
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
#include "libft.h"
char *ft_strjoin(char const *s1, char const *s2)
{
int i;
int j;
int index;
int len;
char *str;
i = 0;
j = 0;
index = 0;
len = ft_strlen(s1) + ft_strlen(s2);
str = malloc(sizeof(char) * (len + 1));
if (!(str))
return (0);
while (s1[i])
str[index++] = s1[i++];
while (s2[j])
str[index++] = s2[j++];
str[index] = '\0';
return (str);
}
|
cs |
- 주의사항 : 문자열의 길이 len이 아닌, len + 1 만큼 동적할당하는 것을 유의해야 한다. (끝의 null을 채워주기 위한 공간까지 할당)
예를 들어, 문자열 abcde라는 문자의 길이는 5이다. 그러나 5칸 + null을 끝에 채우기 위한 1칸의 메모리가 필요하므로 실제 할당할 길이는 len + 1이 되야한다.
또한 문자열이 빈 문자열이라면, \0으로 된 1칸짜리 문자열과 다름이 없다. 따라서 이를 복사하기 위해서는 1칸의 공간을 동적할당 해준 뒤 '\0'을 첫칸에 채워주면 된다.
- 두 문자열의 길이를 더한 길이 + 1(널문자 넣을 공간) 만큼 malloc으로 동적할당한다.
- str(동적할당 된 메모리)에 첫번째 문자열을 복사해준 뒤, 이어서 그 자리부터 두번째 문자열을 복사해서 붙여준다.
- 복사가 완료된 str의 끝에 null을 넣어준 뒤 str의 포인터를 리턴한다.
(3) ft_strtrim
: 주어진 문자열의 앞뒤에서, 주어진 문자집합(set)에 포함된 문자들을 전부 제거한 문자열을 구한다.
- 구현 코드 예시 :
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
|
#include "libft.h"
static int is_charset(char const *set, char c)
{
int i;
i = 0;
while (set[i])
{
if (set[i] == c)
return (1);
i++;
}
return (0);
}
static size_t get_start(char const *s1, char const *set)
{
size_t start;
start = 0;
while (is_charset(set, s1[start]) && s1[start])
start++;
return (start);
}
static size_t get_end(char const *s1, char const *set)
{
size_t end;
end = ft_strlen(s1) - 1;
while (is_charset(set, s1[end]) && end >= 0)
end--;
return (end);
}
char *ft_strtrim(char const *s1, char const *set)
{
char *p;
size_t index;
size_t start;
size_t end;
size_t size;
if (*set == 0)
return (ft_strdup(s1));
start = get_start(s1, set);
if (start == ft_strlen(s1))
size = 1;
else
{
end = get_end(s1, set);
size = end - start + 2;
}
index = 0;
if (!(p = malloc(sizeof(char) * size)))
return (0);
while (start <= end && s1[start])
p[index++] = s1[start++];
p[index] = '\0';
return (p);
}
|
cs |
- 주의사항 : 구한 start 값이 ft_strlen(s1)과 같게 나올 경우, 주어진 문자열 s1 모두에서 set의 문자열이 나온다는 뜻이다. 이때 charset의 문자열을 제거한 문자열을 만들게 되면, 1칸만 동적할당 해준 뒤, 그 속에 null을 넣어주고 그 포인터를 리턴해야한다.
- 주의사항 : 이때 start를 ft_strlen(s1)과 "=="라는 비교연산자로 비교하게 되는데, ft_strlen()의 리턴형은 size_t이기 때문에, 비교할 값인 start 또한 같은 형식으로 선언해주었다.
- 주의사항 : 동적할당할 공간의 사이즈를 구할 때, start와 end 지점이 같을 때에도 해당 지점을 포함하여 null을 할당할 공간까지 총 2칸을 할당하게된다. 따라서 size 는 end - start + 2 가 된다.
- 주의사항 : set이 null일 경우는 ft_strdup()함수를 이용하여 s1의 사본의 포인터를 리턴해주는 식으로 예외처리 해주었다
이때, 원본인 s1를 리턴하지 않고 malloc된 사본을 리턴하는 것은 나중에 free가 가능하게 하기 위함이다
- 주의사항 : 처음 구현할 때, 주어진 문자열 s1에서 set에 포함된 문자열을 전부 제거하는 줄 오해하고 잘못 구현한 적이 있다. 반드시 앞뒤에서부터 각각 탐색했을 때, 더이상 나오지 않을때까지 set에 포함된 문자들을 제거한다는 것을 유의해야한다.
- get_start 함수를 통해, 앞에서부터 탐색했을 때, set의 문자열이 더이상 나오지 않는 시작 지점을 구한다.
- get_end 함수를 통해, 뒤에서부터 탐색했을 때, set의 문자열이 더이상 나오지 않는 끝 지점을 구한다
- 필요한 총 공간을 구하여 동적할당한 뒤, 그 공간에 start지점에서 end지점까지의 값들을 반복문을 통해 복사해준다.
- 보완점 : get_start() 와 get_end() 대신에 이미 이전에 구현한 strchr()과 strrchr()을 사용하면 됬는데, 괜히 함수를 더 만들어 코드의 재사용성과 효율성을 떨어뜨린 것 같다. 동료평가 때 피드백을 받아 알게 되었다. 다시 코드를 짜게 된다면 이 점을 보완하고 싶다.
'IT > 42Seoul' 카테고리의 다른 글
| [Libft] C 언어 라이브러리 구현_Part2_추가함수 구현3 (0) | 2021.05.23 |
|---|---|
| [Libft] C 언어 라이브러리 구현_Part2_추가함수 구현2 (0) | 2021.05.23 |
| [Libft] C 언어 라이브러리 구현_Part1_malloc을 사용한 함수 (0) | 2021.05.20 |
| [Libft] C 언어 라이브러리 구현_Part1_문자 판별 + 변환 관련 함수 (0) | 2021.05.20 |
| [Libft] C 언어 라이브러리 구현_Part1_문자열 관련 함수 (0) | 2021.05.20 |
42서울 : 라피신 후기 + 본과정 합격 후기 (4기 2차 : 3 /22 ~ 4/16)
실은 후기를 쓸까 말까 고민을 많이 했었습니다... 42서울에서는 비밀유지 서약이라는 것을 해서, 중요한 사항을 누설하면 안되기 때문입니다.
그렇지만 문득 제가 라피신 시작 전 많은 블로그로부터 참고했던 생각이 나니 일단 후기글이라도 적자 싶었습니다. 그래서 실제 라피신 진행 과정에 대해서는 구체적인 내용은 최대한 자제하고 감상 위주의 글이 될 것 같습니다.
문제 시 댓글 주시면 바로 글 삭제하겠습니다. 감사합니다.
그럼 시작~
일단 나는 4기 2차로 라피신을 진행하였다.
라피신은 42서울 본과정을 진행하기 위한 1달간의 예선 과정이라고 보면 된다.
4기는 1차와 2차에 거쳐 진행되었는데, 나는 2차에 신청을 했다. 1차 과정 사람들은 내가 라피신 진행하기 전에 이미 1달간의 라피신 과정을 마친 상태였다.
* 신청 관련
1차와 2차 모두 각각 300명씩 신청을 받아 총 인원이 600명 정도 되는데, 4기 본과정에는 250명만이 선발된다. 약 40% 만 선발되는 셈이다.
라피신 신청은 사전온라인테스트 -> 체크인미팅 -> 라피신 신청 의 3단계(내 기억상으론)로 나눠져있으니 꼭 매번 광클 경쟁을 통해 3단계를 모두 참가해야한다.
나는 학교 동기 친구와, 그 친구의 친구들까지해서 나포함 4명이 다같이 지원을 했고, 전부 라피신 신청에 성공했다! (정말 운이 좋았던 케이스다. 보통 어마어마한 경쟁률로 인해 친구들 중 1명만 신청에 성공한 케이스가 많다)
참고로 난 얼마 전까지 코딩을 엄청 못하던 전공자고, 미리 라피신을 위해 휴학을 냈다.
근데 그거 아시나? 라피신은 일생 한번만 가능하다. 즉 떨어지면 다시 재피신이 불가능하다는 거다... (물론 42서울이 국제적인 프로그램인만큼 여러나라에 캠퍼스가 존재하는데, 실리콘벨리 지점에서는 재피신이 가능하다고 듣긴했다)
그러니 라피신을 할 때 만반의 준비를 하고 가서 후회없을만큼 최선을 다하길 권장한다. 꼭 본과정을 가고 싶다는 목표가 있다면 말이다.
또, 라피신은 매번 구성원이 다른만큼, 본과정 합격의 난이도도 달라질 수가 있다.
나도 사전조사를 많이 하고 간 편인데, 이번 기수가 다른 기수에 비해 상향 평준화 되었다는 생각이 조금 들었다. (개인적인 감상이다) 그리고 전공자가 생각보다는(?) 좀 있었다. 아무래도 지금 시국이 시국인지라, 대학이 원격으로 강의를 진행하고, 또 라피신도 격일 출석제로 바뀌었다보니..라피신과 학교를 병행하기가 쉬워진 탓인 것 때문인 듯도 싶었다. 또 요즘 전반적인 취업 침체기라 전공자들도 취업이 힘들다보니, 아무래도 이런 대외 활동에 많이 참여하는 듯 싶다. 심지어는 현업자들도 다양한 경험을 통해 이력서에 장점을 더하기 위해 일을 그만두고 참가하러 온 사람들이 보였다.
그렇지만, 라피신의 좌우명 중 하나가 Life is unfair 이다. 어차피 인생은 불공평하다. 어쩔 수 없지만 운도 실력이다. 불공평한 세상이지만 열심히 노력해서 원하는 것을 이뤄내는 수 밖에 없다. 그러니 불평보다는 노력으로 커버하자.
그렇지만 C언어를 아무 것도 모르고 노베이스로 오는 것만은 말리고 싶다. 라피신은 초보용 교육과정이라기보다는, 프랑스어 그대로 수영장에 빠뜨려놓고 살아남는지 확인하는 예선과정이다. 물론 한달이라는 시간동안 노력하면 안되는 것은 없겠지만...다들 포인터 정도까지는 공부하고 오는 만큼, 상대적으로 격차가 나기 때문에 조급해질 수 있다.
또한 짧은 시간동안 갑자기 많은 양을 급하게 공부하다보면, 개념에 대한 이해가 허술해지고 이는 낮은 시험 성적으로 나타날 가능성도 있다. (매주 금요일에 시험을 본다). 그러니 미리미리 어느정도는 하고와야 고생이 덜하다.
나와 내 친구들은 방학 동안 미리 코딩학원을 다니며 정말 하루도 안빠지고 열심히 공부했다. 그래서 재귀까지는 끝내고 갔다.
그래서 나름대로 수월하게 라피신을 진행할 수 있던 것 같다. 그리고 대부분 포인터까지는 공부하고 오시더라... 요즘 사교육 좋다. 개인적으로 코딩이 심적으로 진입장벽이 높은 편이라고 생각한다. 그래서 첫 스타트는 학원 다니면서 주입식 교육으로 덜 부담스럽게 접근하는 것도 한 방법인 것 같다. 내 경험 상 코딩 생초보로 독학하면 조금 버겁더라.
아예 노베이스로 오신 분들도 보였는데, 몇몇은 잘하는 분들과 친하게 지내며 열심히 배우고자하는 태도로 계속 물어보고 다니며 빠르게 배우셨다. 그렇지만 아무래도 정말 여기에서 강사가 코딩을 가르쳐주는 줄 알고 일종의 학원인 줄 알고 오신 분들은, 인간관계 구축도 힘들어하시고 대부분 마지막 주까지 버티지 못하셨다.
라피신은 동료학습을 권장하기 때문에 이것저것 옆사람에게 물어볼 수 있다. 그렇지만 절대 누가 알아서 가르쳐주진 않는다. 본인이 자기 몫 찾아먹는 연습부터 해야한다. 얼굴에 철판 깔고 가서 무작정 물어봐도 다 알아서 잘 가르쳐주시니 걱정하지 말자. 최선을 다하자!
* 생활 관련
라피신에서 보는 대부분의 사람들은 열심히 한다. 그것도 정말 열심히 한다. 간절함이 눈에 서려있다.
이건 말로 설명하기 힘들다. 한번 와서 보면 안다.
비전공자분들이 직장을 퇴사하고 여기 온 경우가 정말 많다. 그래서 정말 최선을 다하신다. 그렇기 때문에 절대 안일한 태도로 임하면 안된다. 후회가 없을만큼 최선을 다하자.
본과정 선발 기준에 대한 소문이 많긴한데... 나도 정확히는 모른다. 근데 과제 진도를 어느정도 진행하고 시험을 잘보면 대부분 붙긴한다.
꼭 그렇진 않아도 열심히 한 흔적이 보이는 분이면 간혹 붙기도 하더라.
아무래도 클러스터(컴퓨터실)에 출석해야만 동료평가와 동시에 과제 채점을 받을 수 있는데, 이번에는 격일 출석제고 원격평가도 안되었던 기수라 모두들 좀 시간과 여유가 없긴 했다. 그래서 동료학습을 진행하기 좀 힘든 감이 있었다.
또...새벽 1시가 되어도 집에 간 사람들이 드물었다. 다들 정말 열심히한다.
첫주차에는 다들 패닉에 빠지기도 하지만, 점점 갈수록 적응하는 게 보였다. 1주차에 다들 스터디그룹을 형성해서, 출석 가능일이 아닌 날에는 다들 카페나 스터디카페에 모여서 공부한다. 물론 3주차가 고비라 사람들이 좀 줄어들긴 하지만 4주차인 마지막 주차에는 아예 포기하지 않은 사람들 아니면 다들 열심히 막판스퍼트를 달린다. 다음날 아침까지 달리시는 분들 적지 않다.
그러니 체력적 시간적으로도 아무래도 강남까지 매일 멀리서 오기도 힘들고, 차 끊긴 시간에 귀가하기도 힘드니까, 그냥 근처에 여럿이서 숙소를 잡는 것을 권장한다. 고시원도 나쁘진않긴한데 아무래도 잘맞는 사람들끼리 있다면 그거의 60퍼센트 가격에 애어비엔비 장기랜트(27일 이상)으로 훨씬 좋은 숙소 구할 수 있다. 어차피 출석날에는 새벽까지 클러스터에 남아있고, 출석 안하는 날에는 강남 카페에 모여서 스터디하니까 집에 오래 있을 필요도 없다. 그러니 잠자리가 좋은 곳만 구하면 된다. 나도 친구들이랑 애어비앤비 잡아서 근처에 살았다. 그런데 같이 사는게 여러모로 정보 공유 측면에서도 좋고 같이 밥 먹고 가끔은 배달음식 먹으며 스트레스도 풀고,,,생활하기도 나쁘지 않았다.
친구들이 다들 착하고 배려하는 성격이라, 고맙게도 편하게 생활한 것 같다.
* 본과정 합격 소감
아무래도 합격 기준이 모호하다는 소문이 많이 도는 만큼, 정말 많이 걱정했다. 밤새가며 열심히 했지만, 내가 걱정이 많은 성격인만큼, 그래도 떨어지지 않을까 전전긍긍했다. 그렇지만 열심히 참여한 결과 얻은 성과는 정말 좋았다. 같이 참여한 친구들 모두 합격했고, 같이 했던 스터디원들도 1분 제외하고 전부 붙었다. 기쁘다. 세전 100씩 매달 받으며 최대 2년간 공부할 수 있는 것이 본과정의 큰 혜택이고, 그 기간동안 내세울 만한 프로젝트 결과물과 실력을 쌓을 수 있다는 점 또한 매우 기대된다.
하고 싶은 게 아주 많다~
그리고 현재 libft 과제 진행 중인데, 본과정은 좋기도 좋지만 역시 힘든 것 같다...ㅋㅋㅋㅋㅋ
열심히 과제에 굴려지면서 개발자가 지녀야할 구글링 + 자료조사 능력이 좋아지는 느낌을 받는다.
블로그를 할 생각이 없었는데도, 과제를 위해 자료조사를 해놓다보니 그냥 그걸 정리하는 김에 포트폴리오 겸 겸사겸사 하게 되기도 했다.
휴학 기간에 할 게 없으면 사람이 늘어져서 허송세월 보내게 되니 큰일인데, 커리큘럼이 잘 짜여져 있는 대외활동에 참가할 자격을 얻어서 시간을 값지게 보낼 수 있게 된 것에 정말 감사하다고 느낀다!
하여간 라피신 때 고생도 했지만 추억이 많이 생겼다. 밤새고 나오는 아침에 친구들이랑 같이 햄버거 사먹고 숙소 돌아가서 씻고 진짜 소처럼 늘어지게 잤던 생각이 아직도 난다...그리고 내가 잠버릇으로 이를 갈고 옆사람을 때린다는 걸 듣게 된 것도... ㅋㅋㅋㅋㅋ
내가 체력이 안좋은 편이라 당시엔 좀 피곤하고 힘들었지만 뒤돌아보니까 추억이 된게 신기한 것 같다 ㅎㅎ
그리고 라피신 과정 이후로 커피 먹는 양이 많이 늘었다 ㅋㅋㅋㅋㅋ
하여간 이쯤하고 마무리한다.
'Experience > 주제별' 카테고리의 다른 글
| 인프라를 지망하게 된 계기 (Kubernetes & Golang 관련 계획) + 뻘글 (0) | 2025.06.09 |
|---|---|
| Azure AI Developer 해커톤 (수상내역) / 회고록 (0) | 2025.05.02 |
| 2022년도 1월 - 연구실 인턴 합격 회고 (0) | 2022.01.22 |
| [자기계발] 게으름을 고쳐보자! 만원챌린지 (0) | 2021.11.08 |
[Libft] C 언어 라이브러리 구현_Part1_malloc을 사용한 함수
혹시나 문제가 된다면 바로 비공개 처리하겠습니다. 지적이나 댓글 환영합니다!
이번 포스팅에서는 malloc을 사용한 함수 2개 (calloc, strdup)를 구현해보겠다.
malloc을 통해 동적할당을 할 수 있고, 이를 통해 메모리를 더욱 유연하고 자유롭게 쓸 수 있다.
참고로, 내가 정의한 libft.h 헤더에는 <unistd.h>와 <stdlib.h>가 include 되어있다. 따라서 libft.h를 호출하면, 따로 정의하지 않고도 <unistd.h> 에 정의된 size_t 타입과 <stdlib.h>의 malloc/free를 사용할 수 있다.
(1) calloc : 0으로 초기화된 메모리를 할당
- 매뉴얼(영문번역) :
이름 : calloc -- 메모리 할당
시놉시스 :
#include <stdlib.h>
void *calloc(size_t count, size_t size);
설명 :
calloc() 함수는 메모리를 할당한다. 할당된 메모리는 그것이 어느 데이터 타입이든 쓸 수 있게 정렬된다.
(이때 타입은 AltiVec-와 SSE-관련 타입들을 포함한다)
free() 함수를 통해 이러한 메모리 할당 함수로 할당된 메모리를 해제할 수 있다.
calloc() 함수는 size로 주어진 바이트의 메모리를 가진 count 개수의 객체들을 위한 충분한 공간을
연속적으로 할당한다. 그리고 할당된 메모리의 포인터를 반환한다.
할당된 메모리들은 0값을 가진 바이트들로 채워진다
리턴값 : 성공할 경우, 할당된 메모리의 포인터를 반환한다.
만일 오류가 발생한다면, NULL 포인터를 반환한 후 errno를 ENOMEM으로 설정한다.
- 구현 코드 예시 :
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
#include "libft.h"
void *ft_calloc(size_t count, size_t size)
{
size_t i;
unsigned char *ptr;
if (!(ptr = malloc(size * count)))
return (0);
i = 0;
while (i < size * count)
{
ptr[i] = 0;
i++;
}
return ((void *)ptr);
}
|
cs |
- malloc을 통해 size * count만큼 메모리를 할당해주었다
- ptr 이 null(0)일 경우, 메모리 할당이 실패했으므로 ptr을 반환하여 null 포인터를 반환한다.
- 성공적으로 메모리를 할당한 경우, size * count 만큼의 메모리 영역에 unsigned char 형의 포인터를 통해 1바이트씩 접근한다. 그리고 매번 0을 할당하여 할당한 메모리 영역을 모두 0으로 초기화한다
- 메모리 초기화까지 성공하면 (unsigned char *) 형의 ptr을 (void *)로 형변환하여 리턴해준다.
- 참고) errno를 ENOMEM으로 설정한다는 것의 의미
errno는 에러가 발생할 때 마다 기록을 저장하고 있는 전역변수이다.
errno 전역 변수는 프로그램이 시작할 때 "에러가 발생하지 않았다"는 뜻의 0으로 시작해서, 에러가 발생할 때마다 새로운 에러 번호로 갱신된다. (매번 갱신되는 것이 아니라 에러 발생 시 마다 갱신)
ENOMEM : not enough memory (kernel이 사용할 수 있는 메모리 부족)
- 주의) malloc() 실패 시의 널가드를 뺴먹지 말아야한다 (이걸로 동료평가 디팬스 실패했었음)
실제 라이브러리의 calloc()을 호출하여 결과를 확인한 경우, size * count 가 메모리 주소 범위를 벗어날 경우, 메모리 주소로 0이 들어가는 결과가 출력된다.
이를 유의하여 동일하게 구현할 수 있도록 주의해야한다.
(2) strdup : 메모리 할당 및 문자열 복사
- 매뉴얼(영문번역) :
이름 : strdup -- 문자열의 사본을 저장
라이브러리 : 표준 C 라이브러리 (libc, -lc)
시놉시스 :
#include <string.h>
char *strdup(const char *s1);
설명 :
strdup() 함수는 문자열 s1의 사본을 저장하기 위한 충분한 메모리를 할당한다. 그리고 복사를 수행한다.
그리고 그것에 대한 포인터를 반환한다. 해당 포인터는 그 후에 free()의 인자로 사용될 수 있다.
할당할 수 있는 메모리가 불충분할 경우, NULL이 반환되며, errno가 ENOMEM으로 설정된다.
리턴값 : 성공할 경우, 할당된 메모리의 포인터를 반환한다.
만일 오류가 발생한다면, NULL 포인터를 반환한 후 errno를 ENOMEM으로 설정한다.
- 구현 코드 예시 :
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
#include "libft.h"
char *ft_strdup(const char *s1)
{
char *ptr;
size_t len;
size_t i;
i = 0;
len = ft_strlen(s1);
ptr = malloc(sizeof(char) * (len + 1));
if (!(ptr))
return (0);
while (i < len)
{
ptr[i] = s1[i];
i++;
}
ptr[i] = '\0';
return (ptr);
}
|
cs |
- 우선 주어진 문자열의 길이 + 1 만큼 공간을 할당해 주었다.
- ptr에 동적할당이 실패한 경우 (하드웨어의 여유 메모리 부족 등 여러가지 원인), null을 반환한다.
- 동적할당 된 포인터에 주어진 문자열을 복사한 후, 끝에 null을 넣고 해당 포인터를 리턴한다.
- 문자열의 길이값을 size_t 형의 변수 len으로 받았기 때문에, while 문의 조건식에서 len과 비교해야하는 인덱스 변수 i 또한 size_t로 선언해주었다.
참고 자료 출처 :
'IT > 42Seoul' 카테고리의 다른 글
| [Libft] C 언어 라이브러리 구현_Part2_추가함수 구현2 (0) | 2021.05.23 |
|---|---|
| [Libft] C 언어 라이브러리 구현_Part2_추가함수 구현1 (0) | 2021.05.23 |
| [Libft] C 언어 라이브러리 구현_Part1_문자 판별 + 변환 관련 함수 (0) | 2021.05.20 |
| [Libft] C 언어 라이브러리 구현_Part1_문자열 관련 함수 (0) | 2021.05.20 |
| [Libft] C 언어 라이브러리 구현_Part1_mem관련 함수 (0) | 2021.05.17 |
[Libft] C 언어 라이브러리 구현_Part1_문자 판별 + 변환 관련 함수
혹시나 문제가 된다면 바로 비공개 처리하겠습니다. 지적이나 댓글 환영합니다!
이번 포스팅에서는 문자 판별 + 변환 함수에 관한 내용을 정리하겠다.
참고로, 내가 정의한 libft.h 헤더에는 <unistd.h>와 <stdlib.h>가 include 되어있다. 따라서 libft.h를 호출하면, 따로 정의하지 않고도 <unistd.h> 에 정의된 size_t 타입과 <stdlib.h>의 malloc/free를 사용할 수 있다.
(1) isalpha : 문자가 알파벳인지 판별
- is + alphabet
- 매뉴얼(영문번역) :
이름 : isalpha -- 알파벳 문자인지 판별
라이브러리 : 표준 C 라이브러리 (libc, -lc)
시놉시스 :
#include <ctype.c>
int isalpha(int c);
설명 :
isalpha() 함수는 isupper() 또는 islower()이 참이 되게 하는 문자를 판별한다.
인자로 전달된 값은 (unsigned char) 형으로 표현되거나 EOF의 값으로 표현되어야한다.
리턴값 : 문자 판별 값이 false일 경우 0을 리턴하며, 문자 판별 값이 true일 경우 0이 아닌 값을 리턴한다.
- 구현 코드 예시 :
|
1
2
3
4
5
6
7
8
9
|
#include "libft.h"
int ft_isalpha(int c)
{
if ((c >= 'A' && c <= 'Z') || (c >= 'a' && c <= 'z'))
return (1);
return (0);
}
|
cs |
- '0이 아닌 값'을 리턴하므로, 사실 어떤 값을 리턴해도 상관없다.
그렇지만 ctype헤더에서 islapha()를 직접 import해서 출력한 결과, 1과 0으로 결과값이 나오는 것을 확인하고 그대로 구현하였다.
- 알파벳을 판별하므로, 소문자 또는 대문자인 것을 판별하였다.
- 참고) 0이 아닌 값 중 어떤 값을 리턴해도 상관없는 이유
C언어에서는 0을 거짓으로, 그 이외의 값을 모두 참으로 사용한다.
따라서 if (isalpha(c))를 실행할 경우, 어떤 값이 리턴되더라도 0만 아니면 if 문의 조건이 참이되어 조건문 속 코드가 실행된다.
(2) isdigit : 문자가 숫자인지 판별
- is + digit
- 매뉴얼(영문번역) :
이름 : isdigit -- 10진수-숫자 문자인지 판별
라이브러리 : 표준 C 라이브러리 (libc, -lc)
시놉시스 :
#include <ctype.c>
int isdigit(int c);
설명 :
isdigit() 함수는 10진수 숫자인 문자를 판별한다. 그것들은 언어와 상관없이, '0' ~ '9'의 문자만 포함한다.
인자로 전달된 값은 (unsigned char) 형으로 표현되거나 EOF의 값으로 표현되어야한다.
리턴값 : 문자 판별 값이 false일 경우 0을 리턴하며, 문자 판별 값이 true일 경우 0이 아닌 값을 리턴한다.
- 구현 코드 예시 :
|
1
2
3
4
5
6
7
8
9
|
#include "libft.h"
int ft_isdigit(int c)
{
if (c >= '0' && c <= '9')
return (1);
return (0);
}
|
cs |
- 10진수 숫자 문자 '0' ~ '9' 사이의 값이라면 1을 리턴하고, 그렇지 않으면 0을 리턴한다.
(3) isalnum : 문자가 알파벳이나 숫자인지 판별
- is + alphabet + num
- 매뉴얼(영문번역) :
이름 : isalnum -- 알파벳 혹은 숫자 문자인지 판별
라이브러리 : 표준 C 라이브러리 (libc, -lc)
시놉시스 :
#include <ctype.c>
int isdigit(int c);
설명 :
isalnum() 함수는 isalpha() 또는 isdigit()이 참이 되게 하는 문자를 판별한다.
인자로 전달된 값은 (unsigned char) 형으로 표현되거나 EOF의 값으로 표현되어야한다.
리턴값 : 문자 판별 값이 false일 경우 0을 리턴하며, 문자 판별 값이 true일 경우 0이 아닌 값을 리턴한다.
- 구현 코드 예시 :
|
1
2
3
4
5
6
7
8
9
|
#include "libft.h"
int ft_isalnum(int c)
{
if ((c >= 'A' && c <= 'Z') || (c >= 'a' && c <= 'z')
|| (c >= '0' && c <= '9'))
return (1);
return (0);
}
|
cs |
- 알파벳 혹은 숫자 둘 중 하나라면 1을 리턴하고, 그렇지 않으면 0을 리턴한다.
(4) isascii : 문자가 아스키 문자인지 판별
- is + ASCII
- 매뉴얼(영문번역) :
이름 : isascii -- ASCII 문자인지 판별
라이브러리 : 표준 C 라이브러리 (libc, -lc)
시놉시스 :
#include <ctype.c>
int isascii(int c);
설명 :
isacii() 함수는 주어진 문자가 ASCII 문자(0 ~ 0177(8진수))인지 판별한다.
- 구현 코드 예시 :
|
1
2
3
4
5
6
7
8
9
|
#include "libft.h"
int ft_isascii(int c)
{
if (c >= 0 && c <= 127)
return (1);
return (0);
}
|
cs |
- 8진수 0177을 10진수로 변환하면 127이다. 따라서 10진수로 0 ~ 127 범위 내의 값인지 판별한다.
- 아스키 문자 범위에 포함되어 있다면 1을 리턴하고, 그렇지 않으면 0을 리턴한다.
(5) toupper : 문자를 대문자로 변환
- to + Uppercase
- 매뉴얼(영문번역) :
이름 : toupper -- 알파벳 소문자를 알파벳 대문자로 변환
라이브러리 : 표준 C 라이브러리 (libc, -lc)
시놉시스 :
#include <ctype.c>
int toupper(int c);
설명 :
toupper() 함수는 소문자를 그에 대응하는 대문자로 변환한다.
인자로 전달된 값은 (unsigned char) 형으로 표현되거나 EOF의 값으로 표현되어야한다.
리턴값 : 인자가 소문자일 경우, 그에 대응하는 대문자가 있다면 그것을 반환한다.
그렇지 않으면, 바뀌지 않은 채의 인자가 반환된다.
- 구현 코드 예시 :
|
1
2
3
4
5
6
7
8
9
|
#include "libft.h"
int ft_toupper(int c)
{
if (c >= 'a' && c <= 'z')
c -= 32;
return (c);
}
|
cs |
- 아스키코드 상에서 대문자와 소문자의 차이값은 32이다. 그것도 소문자가 아스키코드값이 더 크다.
- 따라서 매개변수로 받은 인자가 소문자일 경우, 인자에서 32를 빼준 후 리턴해준다.
- 참고) 아스키 코드란?
컴퓨터는 0과 1 숫자 밖에 모르기 때문에 문자도 숫자로 기억한다. 이때, 어떤 숫자와 어떤 문자를 대응시키는 가에 따라 여러가지 인코딩 방식이 있는데 통상 아스키 코드 방식을 많이 사용한다.
아스키 코드(ASCII Table)는 0번부터 127번까지만 사용한다. 127번 이후 코드를 사용했던 적도 있었는데 이는 표준이 아니며, 운영체제마다 다른 코드(문자)를 배치했기 때문에 호환이 되지 않는다. 윈도우즈 운영 체제는 현재 128번부터 255번 사이에 포함된 문자를 출력하려는 시도에 대하여 물음표(?)를 출력해서 사용하면 안된다는 것을 알려준다. 128번과 255번 문자는 물음표는 아니지만 사용할 수 없는 문자이다.
- 참고) 아스키 코드 표
제어 문자는 0번부터 31번 문자까지를 모두 포함하지만, 중간에 공백으로 사용되는 문자들이 있어 9번부터 13번 까지를 공백 문자로 처리했다. 표 마지막에 있는 DEL 문자는 제어문자이므로 갈색이다.
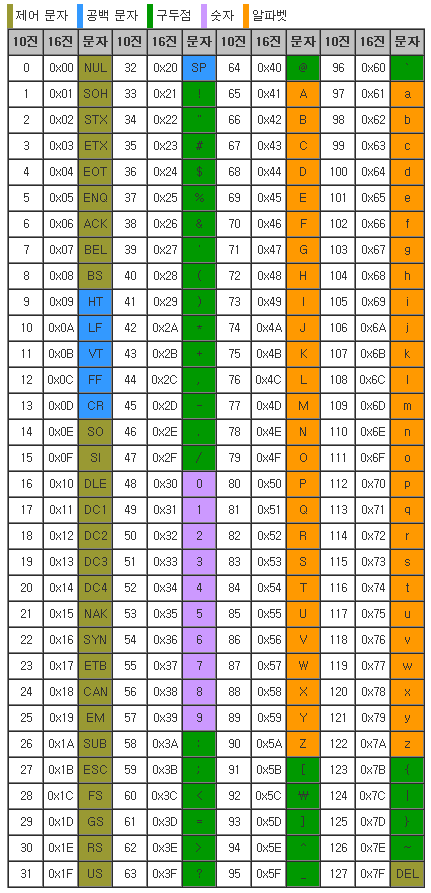
(6) tolower : 문자를 소문자로 변환
- to + Lowercase
- 매뉴얼(영문번역) :
이름 : tolower -- 알파벳 대문자를 알파벳 소문자로 변환
라이브러리 : 표준 C 라이브러리 (libc, -lc)
시놉시스 :
#include <ctype.c>
int tolower(int c);
설명 :
tolower() 함수는 대문자를 그에 대응하는 소문자로 변환한다.
인자로 전달된 값은 (unsigned char) 형으로 표현되거나 EOF의 값으로 표현되어야한다.
리턴값 : 인자가 대문자일 경우, 그에 대응하는 소문자가 있다면 그것을 반환한다.
그렇지 않으면, 바뀌지 않은 채의 인자가 반환된다.
- 구현 코드 예시 :
|
1
2
3
4
5
6
7
8
9
|
#include "libft.h"
int ft_tolower(int c)
{
if (c >= 'A' && c <= 'Z')
c += 32;
return (c);
}
|
cs |
- 아스키코드 상에서 대문자와 소문자의 차이값은 32이다. 그것도 소문자가 아스키코드값이 더 크다.
- 따라서 매개변수로 받은 인자가 대문자일 경우, 인자에서 32를 더해준 후 리턴해준다.
(7) atoi : 문자 변환 함수
- Alphabet to Integer : 문자를 정수로 변환
- 매뉴얼(영문번역) :
이름 : atoi -- ASCII 문자열을 정수로 변환한다
라이브러리 : 표준 C 라이브러리 (libc, -lc)
시놉시스 :
#include <stdlib.h>
int atoi(const char *str);
설명 : atoi() 함수는 str이 가르키는 문자열의 앞 부분을 정수 표현으로 변환한다
리턴값 : 문자열 str을 int형 정수로 변환한 값
- 구현 코드 예시 :
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
#include "libft.h"
static int is_space(char c)
{
if (c == ' ' || c == '\t' || c == '\v'
|| c == '\r' || c == '\f' || c == '\n')
return (1);
return (0);
}
static int is_operater(char c)
{
if (c == '+' || c == '-')
return (1);
return (0);
}
static int check_long_long(unsigned long long nb, int sign)
{
if (nb > 0 && (nb - 1 > 9223372036854775807) && sign == -1)
return (0);
if (nb > 9223372036854775807 && sign == 1)
return (-1);
return (1);
}
int ft_atoi(const char *str)
{
unsigned long long nb;
int i;
int sign;
int ret;
i = 0;
sign = 1;
while (is_space(str[i]))
i++;
if (is_operater(str[i]))
{
if (str[i] == '-')
sign *= -1;
i++;
}
nb = 0;
while (str[i] >= '0' && str[i] <= '9')
{
if ((ret = check_long_long(nb, sign)) != 1)
return (ret);
nb *= 10;
nb += str[i] - '0';
i++;
}
return (sign * (int)nb);
}
|
cs |
- 인자로 받은 문자열을 int 형 숫자로 변환한다.
- 문자열에 int형 최솟값(INT_MIN = -2147483648)이 들어온 경우는 따로 예외처리 해주지 않았다. INT_MAX(2147483647) 값을 초과하므로 자동으로 오버플로우가 발생하여 INT_MIN 값으로 결과가 처리되기 때문이다.
- 앞에 공백이 나오는 부분은 while문으로 인덱스를 계속 증가시켜 지나간다. 그리고 다음에 나오는 부호를 확인한다.
- 문자의 범위가 '0' ~ '9'인 숫자 범위 사이인 경우인 동안, 숫자 변환을 계속한다.
- 문자의 범위가 '0' ~ '9'의 범위가 더이상 아닌 경우(다른 문자나 널 문자가 나온 경우), while문을 중단하고 현재 부호값과 int형으로 캐스팅한 숫자값을 곱하여 결과값인 정수를 리턴한다. 이때 따로 오버플로우는 처리해주지 않는다.
- 내가 만든 check_long_long 함수의 역할
원래 atoi함수에서는, 숫자가 long long 범위를 넘어갈 경우, 0 혹은 -1 을 반환하도록 한다.
부호가 양수일 경우는 -1, 음수일 경우에는 0을 리턴한다.
이 함수는 주어진 문자열이 long_long형을 가질 숫자 문자열인지를 판별한다.
원래 atoi함수가 int형을 리턴하므로 이러한 구현은 필수적이지는 않으며, 그저 권장사항이지만, 기존의 함수를 완벽한 구현하기 위하여 구현하였다.
따라서 nb를 unsigned long long으로 선언하였다. 그리고 주어진 문자열에서 부호를 뺀 숫자부분을 nb에 저장하여, 부호와 함께 long long 범위를 초과하는지를 체크하여, atoi함수와 같은 동작을 수행하도록하였다.
왜인지 모르겠지만 비교연산자 "=="는 long long 범위까지의 비교만 가능한 것 같았다.(아니면 컴파일 에러)
그래서 nb가 long long min인지 보려는 경우에는, 부호를 뺀 양수값으로 만들어 sign값과 함께 확인해야하는데, 이 경우 long long max의 범위를 초과하여 컴파일 에러가 났다.
따라서 if 문의 조건을 nb > 0 && (nb - 1 > long long max)로 수정하였다.
이때 nb > 0 의 조건을 넣지 않으면 언더플로우가 나서 전체적인 결과값에 오류가 난다.
- 참고) 숫자 변환 알고리즘
먼저 숫자값을 저장할 int 형 변수 nb를 0으로 초기화해준다.
현재 인덱스에 나오는 숫자형 문자에서 계속 '0'을 빼서 각 자리 문자를 한자리 숫자로 만들어 주고, nb 변수에 이를 더한다. 다음 인덱스로 넘어갈 때마다 10을 곱해가며 문자가 종료될 때까지 이를 계속한다.
- 참고) static 함수란 무엇인가
static을 붙인 정적함수는 해당 파일에서만 사용할 수 있다. 정적 함수를 사용하면 같은 이름을 가진 함수를 파일마다 만들 수 있다. 따라서 정적 함수는 기능이 여러 파일로 분리되어 있을 때, 각 파일 안에서만 사용하는 기능을 구현할 수 있다.
libft 과제에서는 과제함수 이외의 함수가 해당 파일 내에서만 컴파일되도록하기 위해, 헤더파일에 포함되지 않는 함수에는 static을 사용할 것을 규칙으로 하고 있다.
참고 자료 출처 :
https://dojang.io/mod/page/view.php?id=130
C 언어 코딩 도장: 18.4 if 조건문의 동작 방식 알아보기
C 언어에서 if는 0일 때 거짓, 0이 아닐 때 참으로 동작합니다. 다음 내용을 소스 코드 편집 창에 입력한 뒤 실행해보세요. if_2.c #include int main() { if (2) // 0이 아니므로 참 printf("참\n"); else printf("거
dojang.io
https://shaeod.tistory.com/228
ASCII Table - 아스키 코드표
(아스키코드를 알면 C/C++이나 Java 등으로 문자열 함수를 다루거나 파일 함수를 다룰때 도움이 됩니다.) 컴퓨터는 0과 1 숫자 밖에 모르기 때문에 문자도 숫자로 기억합니다. 이때, 어떤 숫자와 어
shaeod.tistory.com
https://dojang.io/mod/page/view.php?id=691
C 언어 코딩 도장: 79.3 정적 함수 사용하기
이번에는 정적 함수를 알아보겠습니다. 다음 내용을 프로젝트 디렉터리에 print.c로 저장하세요(반드시 프로젝트에 포함해야 합니다). print.c #include void print() // print.c에서 print 함수 선언 및 정의 {
dojang.io
'IT > 42Seoul' 카테고리의 다른 글
| [Libft] C 언어 라이브러리 구현_Part2_추가함수 구현2 (0) | 2021.05.23 |
|---|---|
| [Libft] C 언어 라이브러리 구현_Part2_추가함수 구현1 (0) | 2021.05.23 |
| [Libft] C 언어 라이브러리 구현_Part1_malloc을 사용한 함수 (0) | 2021.05.20 |
| [Libft] C 언어 라이브러리 구현_Part1_문자열 관련 함수 (0) | 2021.05.20 |
| [Libft] C 언어 라이브러리 구현_Part1_mem관련 함수 (0) | 2021.05.17 |
[Libft] C 언어 라이브러리 구현_Part1_문자열 관련 함수
혹시나 문제가 된다면 바로 비공개 처리하겠습니다. 지적이나 댓글 환영합니다!
이번 포스팅에서는 문자열 관련 함수에 관한 내용을 정리하겠다.
참고로, 내가 정의한 libft.h 헤더에는 <unistd.h>와 <stdlib.h>가 include 되어있다. 따라서 libft.h를 호출하면, 따로 정의하지 않고도 <unistd.h> 에 정의된 size_t 타입과 <stdlib.h>의 malloc/free를 사용할 수 있다.
(1) strlen : 문자열 길이 함수
- string + length
- 매뉴얼(영문번역) :
이름 : strlen -- 문자열의 길이를 구한다
라이브러리 : 표준 C 라이브러리 (libc, -lc)
시놉시스 :
#include <string.h>
size_t strlen(const char *s);
설명 : strlen() 함수는 문자열 s의 길이를 연산한다.
리턴값 : strlen() 함수는 문자열 끝의 null 문자가 올 때까지의 문자의 개수를 리턴한다.
- 구현 코드 예시 :
|
1
2
3
4
5
6
7
8
9
10
11
12
|
#include "libft.h"
size_t ft_strlen(const char *str)
{
size_t len;
len = 0;
while (str[len])
len++;
return (len);
}
|
cs |
- while (str[len]) 은 while (str[len] != '\0')와 동일한 의미이다
- 참고) size_t 란 무슨 타입인가? (주의 ! 엄밀히 unsigned int 타입이 아니다)
size_t는 '이론상 가장 큰 사이즈를 담을 수 있는 unsigned 데이터 타입'으로 정의된다. 즉, 32비트 머신에서는 32비트 사이즈의 unsigned 정수형(int가 아니라 그냥 '정수'를 의미함), 64비트 머신에서는 64비트 사이즈의 unsigned 정수형(unsigned long long)이다. 향후 등장할 지도 모르는 128비트 머신이라던가 더 큰 머신이 존재한다면 그에 따라 더 큰 사이즈가 될 것이다.
따라서 unsigned int로 착각하고 int나 unsigned int로 형변환을 해서 사용하다가 범위가 벗어나는 버그가 발생할 가능성이 있으니 유의해두는 게 좋다. 특히 큰 데이터나 큰 용량을 가진 파일을 처리할 때 주의해야할 것이다.
- 참고) (char *) 과 (cosnt char *)의 차이점
(char *) 은 문자열 상수를 가리키지 못하고, (const char *)은 문자열 상수를 가리키지만 그 주소에 다른 값을 씌울 수는 없다. 결국 둘 다 메모리에 있는 임시 문자열 상수에 대한 변화는 불가능하다는 것이다.
따라서 읽기 전용인 (const char *) 자료형을 함수 매개변수로 문자열을 넘길 때 많이 사용하게 된다
- 참고) (const char) 과 (char const) 의 차이점
(const char *)은 (const char)에 대한 포인터이고, (char * const)는 (char)에 대한 상수 포인터이다.
(const char *)은 상수형 문자에 대한 포인터로서, 포인터가 가리키는 변수의 값을 바꿀 수 없다
(char const *)는 문자에 대한 상수형 포인터로, 포인터 값을 바꿀 수 없다
(const char const *)는 상수형 문자에 대한 상수형 포인터로, 포인터가 가리키는 변수의 값과 포인터 값을 바꿀 수 없다.
(2) strlcpy : 문자열 복사 함수
- string + length + copy
- strcpy와 똑같이 데이터를 복사하지만, 보안 목적으로 strcpy를 대신할 함수로 만들어졌다.
- 매뉴얼(영문번역) :
이름 : strlcpy -- size 범위의 문자열을 복사
라이브러리 : 표준 C 라이브러리 (libc, -lc)
시놉시스 :
#include <string.h>
size_t strlcpy(char * restrict dst, char * restrict src, size_t dstsize);
설명 :
- strlcpy()는 destination 버퍼의 전체 사이즈를 받고,
dstsize - 1만큼의 문자들을 문자열 src에서 문자열 dst로 복사한다
- dstsize가 0이 아닐 경우, 결과값 끝에 null을 넣고 종료시킨다.
- 흔히 오용되곤하는 strncpy 함수를 대체할 수 있다. 더 일관적이며, 안전하고, 오류가 적다.
리턴값 : src의 길이를 리턴한다 (생성하고자 했던 string의 총 길이)
유의점 : strlcpy()는 공간이 있을 경우 null로 끝나는 것을 보장한다.
null을 위한 공간이 dstsize에 포함되어있어야함을 유의해야한다
리턴값이 dstsize보다 작을 경우, 복사한 결과 문자열이 잘릴 수 있다.
- 구현 코드 예시 :
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
#include "libft.h"
size_t ft_strlcpy(char *dest, const char *src, size_t dstsize)
{
size_t i;
size_t len;
i = 0;
len = ft_strlen(src);
if (dstsize == 0)
return (len);
while (src[i] && i < dstsize - 1)
{
dest[i] = src[i];
i++;
}
dest[i] = '\0';
return (len);
}
|
cs |
- 어떤 경우에나 src의 길이를 리턴한다.
- dstsize - 1 만큼의 문자들을 src에서 dst로 복사한 후, 끝에 null을 넣고 종료시킨다.
- dstsize는 끝의 null을 포함한 길이를 넣어줘야한다
- 참고) strncpy, strlcpy의 차이점
strncpy에서는 src의 길이가 dst 버퍼의 길이와 같거나 더 길 경우, NULL-terminate 되지 않는다. (null 문자로 종료되지 않는다).
반면 strlcpy는 NULL-terminate를 보장한다. 이 함수는 size - 1 만큼의 string 복사와 함께 NULL로 끝남을 보장해준다. 현재 커널에서는 두 함수 모두 많이 사용되고 있다.
또 strncpy는 문자열에 대한 포인터를 반환하지만, strlcpy는 정수형의 길이를 반환한다는 점 또한 차이점이다.
이는 strn 시리즈와 strl 시리즈의 공통적인 차이점이기도 하다.
(3) strlcat : 문자열 결합 함수
- string + length + concatenate
- 매뉴얼(영문번역) :
이름 : strlcat -- size 범위의 문자열을 연결
라이브러리 : 표준 C 라이브러리 (libc, -lc)
시놉시스 :
#include <string.h>
size_t strlcat(char * restrict dst, char * restrict src, size_t dstsize);
설명 :
- strlcat()는 destination 버퍼의 전체 사이즈를 받고, 문자열 dst의 끝에 문자열 src를 붙인다.
이때, 최대 dstsize - strlen(dst) - 1만큼의 문자들을 결합한다.
- dstsize가 0이거나 원본 dst 문자열이 dstsize보다 긴 경우를 제외하면,
결과값 끝에 null을 넣고 종료시킨다.
- 흔히 오용되곤하는 strncat 함수를 대체할 수 있다. 더 일관적이며, 안전하고, 오류가 적다.
리턴값 :
- 원래 dst의 길이 + src의 길이 (생성하고자 했던 문자열의 총 길이)
- src의 길이 (dstsize가 0인 경우)
- dstsize + src의 길이 (dstsize가 원래 dst의 길이보다 작거나 같은 경우)
유의점 : strlcat()는 공간이 있을 경우 null로 끝나는 것을 보장한다.
null을 위한 공간이 dstsize에 포함되어있어야함을 유의해야한다
리턴값이 dstsize보다 작을 경우, 복사한 결과 문자열이 잘릴 수 있다.
- 구현 코드 예시 :
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
#include "libft.h"
size_t ft_strlcat(char *dest, const char *src, size_t dstsize)
{
size_t i;
size_t len;
len = ft_strlen(dest);
if (dstsize <= len)
return (ft_strlen(src) + dstsize);
i = 0;
while (src[i] && len + i + 1 < dstsize)
{
dest[len + i] = src[i];
i++;
}
dest[len + i] = '\0';
return (ft_strlen(src) + len);
}
|
cs |
- dstsize가 dst의 길이보다 작거나 같은 경우, dstsize와 src의 길이를 더한 값을 리턴한다
- dstsize가 dst길이보다 큰 경우, dst에 총 (dstsize - 1) 개의 문자가 들어갈 때까지 최대한 복사를 수행하고, 끝에 null을 넣어준 다음, 원래 dst의 길이 + src의 길이를 리턴한다
(4) strchr : 문자열 속 문자 탐색 함수
- string + char
- 매뉴얼(영문번역) :
이름 : strchr -- 문자열 속의 어떤 문자의 위치를 찾는다
라이브러리 : 표준 C 라이브러리 (libc, -lc)
시놉시스 :
#include <string.h>
char *strchr(const char *s, int c);
설명 : strchr() 함수는 s가 가리키는 문자열 안에서 (char로 변환된) c가 첫번째로 등장하는 위치를 찾는다.
문자열 끝의 null 문자 또한 문자열의 일부로 간주한다.
그러므로 c가 '\0'일 경우, 함수는 문자열 끝의 '\0'의 위치를 찾는다.
리턴값 : 찾은 문자의 위치를 가르키는 포인터를 반환한다.
만일 문자열에서 그 문자를 찾지 못하면, null을 반환한다
- 구현 코드 예시 :
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
#include "libft.h"
char *ft_strchr(const char *s, int c)
{
size_t i;
i = 0;
if ((unsigned char)c == '\0')
return ((char *)(s + ft_strlen(s)));
while (s[i])
{
if (s[i] == (unsigned char)c)
return ((char *)(s + i));
i++;
}
return (0);
}
|
cs |
- 주의할 점 : (unsigned char) 형으로 비교를 수행
- null 문자 또한 문자열의 일부로 간주하므로, 찾고자 하는 문자가 널 문자일 경우를 미리 예외처리 해주었다.
- 문자열의 맨 앞에서부터 탐색을 수행한다
- 문자열에서 찾은 특정 문자의 위치를 반환한다.
- 문자열에서 해당 문자를 찾지 못하면 0을 반환한다.
- (const char *) 형인 s[i] 위치를 리턴하기 위해 (char *)형으로 형변환 한 후 리턴하였다
(5) strrchr : 문자열 속 문자 탐색 함수
- string + reverse + char
- 매뉴얼(영문번역) :
이름 : strrchr -- 문자열 속의 어떤 문자의 위치를 찾는다
라이브러리 : 표준 C 라이브러리 (libc, -lc)
시놉시스 :
#include <string.h>
char *strrchr(const char *s, int c);
설명 : strrchr() 함수는 s가 가리키는 문자열 안에서 (char로 변환된) c가 마지막으로 등장하는 위치를 찾는다.
그 외의 동작은 strchr()함수와 같다.
리턴값 : 찾은 문자의 위치를 가르키는 포인터를 반환한다.
만일 문자열에서 그 문자를 찾지 못하면, null을 반환한다
- 구현 코드 예시 :
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
#include "libft.h"
char *ft_strrchr(const char *s, int c)
{
size_t i;
size_t len;
len = ft_strlen(s);
if ((unsigned char)c == '\0')
return ((char *)(s + len));
i = 1;
while (i <= len)
{
if (s[len - i] == (unsigned char)c)
return ((char *)(s + len - i));
i++;
}
return (0);
}
|
cs |
- 주의할 점 : (unsigned char) 형으로 비교를 수행
- null 문자 또한 문자열의 일부로 간주하므로, 찾고자 하는 문자가 널 문자일 경우를 미리 예외처리 해주었다.
- 문자열의 맨 뒤에서부터 탐색을 수행한다
- 문자열에서 찾은 특정 문자의 위치를 반환한다.
- 문자열에서 해당 문자를 찾지 못하면 0을 반환한다.
- (const char *) 형인 s[i] 위치를 리턴하기 위해 (char *)형으로 형변환 한 후 리턴하였다
- s[len - 1] (null 문자 바로 전) 부터 s[0]까지 탐색하는데, i = 0으로 설정할 경우, s[len - 1 - i] 로 코드가 복잡해져서 i = 1로 설정하였다.
(6) strnstr : 문자열 속 문자열 탐색 함수
- string + n + string
- 매뉴얼(영문번역) :
이름 : strnstr -- 문자열 속 부분 문자열의 위치를 찾는다
라이브러리 : 표준 C 라이브러리 (libc, -lc)
시놉시스 :
#include <string.h>
char *strnstr(const char *haystack, const char *needle, size_t len);
설명 : strnstr() 함수는 haystack 이라는 문자열 속,
처음으로 등장하는 needle 문자열(null로 끝남)의 위치를 찾는다. 이때 최대 len만큼 문자를 탐색한다.
'\0'(널문자) 이후에 나오는 문자들은 탐색하지 않는다.
리턴값 :
- needle이 빈 문자열일 경우, haystack을 리턴한다;
- 만일 needle이 haystack에 존재하지 않는 경우, null을 리턴한다
- 만약 needle이 haystack에 존재한다면, needle의 첫번째 문자의 위치를 리턴한다
- 구현 코드 예시 :
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
#include "libft.h"
char *ft_strnstr(const char *haystack, const char *needle,
size_t len)
{
size_t i;
size_t j;
size_t length;
length = ft_strlen(needle);
if (length == 0)
return ((char *)haystack);
i = 0;
while (haystack[i] && i < len)
{
j = 0;
while (needle[j] && i + j < len)
{
if (haystack[i + j] != needle[j])
break ;
j++;
}
if (!(needle[j]))
return ((char *)haystack + i);
i++;
}
return (0);
}
|
cs |
- 최대 len 만큼 문자열을 탐색한다.
- needle이 빈 문자열일 경우(= needle의 길이가 0 일 경우), (char *)로 형변환한 haystack을 리턴하였다.
- haystack에서 needle이 존재하는 경우 (= needle의 끝(null 이전)까지 비교가 수행된 경우), haystack에서 needle이 등장하는 첫 위치를 리턴한다.
- needle이 haystack에 존재하지 않는 경우 0을 리턴하였다.
(7) strncmp : 문자열 비교 함수
- 매뉴얼(영문번역) :
이름 : strncmp -- 문자열들을 비교한다
라이브러리 : 표준 C 라이브러리 (libc, -lc)
시놉시스 :
#include <string.h>
int strncmp(const char *s1, const char *s2, size_t n);
설명 : strncmp() 함수는 null로 끝나는 문자열 s1, s2에서 최대 n개만큼 문자를 비교한다.
strncmp()는 2진수 데이터보다는 문자열을 비교하기 위해 고안되었기 때문에,
'\0'(널문자) 이후의 문자들은 비교되지 않는다
리턴값 : s1이 s2보다 값이 큰 지, 같은 지, 작은 지에 따라 리턴값이 달라진다.
각 경우에 양수, 0, 음수를 반환한다.
비교는 unsigned char을 이용하여 진행되므로, '\200'이 '\0'보다 크다.
- 구현 함수 예시 :
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
#include "libft.h"
int ft_strncmp(const char *s1, const char *s2, size_t n)
{
size_t i;
if (n == 0)
return (0);
i = 0;
while (s1[i] && s2[i] && i + 1 < n)
{
if (s1[i] != s2[i])
break ;
i++;
}
return ((unsigned char)s1[i] - (unsigned char)s2[i]);
}
|
cs |
- 최대 n 개만큼 문자를 비교한다.
- 비교가 (unsigned char)로 수행된 다는 점을 주의하여, s1와 s2의 차이값을 (unsigned char)로 비교하여 리턴하였다.
- (unsigned char) 형의 차이값을 리턴할 때 int 형으로 자동적 형변환이 일어나므로, 굳이 명시적 형변환을 하지 않았다.
- null 문자 이후의 문자들은 비교되지 않는다는 점을 고려하여, while문의 조건으로 s1과 s2가 모두 null이 아닐 때 반복을 수행하게 하였다
참고) C언어 형 변환(캐스팅) 시 주의점
문자(아스키코드, 언어)를 형변환 할 때에는 unsigned char로 캐스팅하는 것이, 이후의 int형 형변환에서 안전하다.
https://swimminglab.tistory.com/69
C 언어 형 변환(캐스팅)시 주의할 점
예를 들어서 11001111이라는 char 형의 데이터가 있다고 하자. 그런데 아스키 코드에 있는 영어만 사용할 것이 아니고 한글을 사용하고 싶은 경우가 있을 수 있다. 참고로 한글은 '가'라는 한 글자를
swimminglab.tistory.com
참고자료 출처 :
https://code4human.tistory.com/112
[C언어] 내장함수 비교 - strlcpy, strlcat
앞서 의 strcpy, strncpy, strlcpy의 차이를 정리했다. 그 중 strlcpy는 strlcat과 유사하다. 실제로 man 가이드는 이 둘을 같이 안내한다. 간단히 차이점을 정리해본다. strlcpy PROTOTYPE #include size_t strl..
code4human.tistory.com
https://noel-embedded.tistory.com/1171
char *과 const char *
char *, const char * 둘의 차이는 문자 상수를 참조할 수 있느냐의 여부에 있다. 다음과 같이 컴파일 에러와 표현되지 않은 식을 보면서 대략 유추할 수 있다 char*은 문자열 상수를 가리키지 못하고, c
noel-embedded.tistory.com
[c++] 항상 헷갈리는 const 위치에 따른 쓰임새 차이 (const char , char const)
■ ( const char * ) 상수형 문자에 대한 포인터. 포인터가 가리키는 변수의 값을 바꿀 수 없음 #include int main() { char ch1 = 'a'; char ch2 = 'b'; const char * pch; pch = &ch1; std::cout << *pch << s..
simplesolace.tistory.com
https://blog.dasomoli.org/478/
[Linux:Kernel] strncpy 대신 strlcpy – DasomOLI는 다솜돌이라구요~!
이 글에 있는 모든 코드는 GPL License를 따릅니다(All code attached is released under the GPL License in this article). strncpy 에서는 source의 길이가 destination의 버퍼 길이와 같거나 더 길 경우, NUL-terminate되지 않는
blog.dasomoli.org
([C언어] 24강) "자동적 형변환"과 "명시적 형변환"
안녕하세요! 잭클입니다! 이번 시간에는 자동적 형변환과 명시적 형변환에 대해서 배울건데요 (약간 늦은 감이 있네요 뒤죽박죽 순서 죄송합니다..ㅠㅠ) 자 우선 어렵지 않으니 바로 코드부터
jeckl.tistory.com
'IT > 42Seoul' 카테고리의 다른 글
| [Libft] C 언어 라이브러리 구현_Part2_추가함수 구현2 (0) | 2021.05.23 |
|---|---|
| [Libft] C 언어 라이브러리 구현_Part2_추가함수 구현1 (0) | 2021.05.23 |
| [Libft] C 언어 라이브러리 구현_Part1_malloc을 사용한 함수 (0) | 2021.05.20 |
| [Libft] C 언어 라이브러리 구현_Part1_문자 판별 + 변환 관련 함수 (0) | 2021.05.20 |
| [Libft] C 언어 라이브러리 구현_Part1_mem관련 함수 (0) | 2021.05.17 |
[Libft] C 언어 라이브러리 구현_Part1_mem관련 함수
혹시나 문제가 된다면 바로 비공개 처리하겠습니다. 지적이나 댓글 환영합니다!
각 항목 아래 더보기를 클릭하시면 더 자세한 설명을 펼쳐서 볼 수 있습니다~
어느덧 42서울 본과정생(카뎃)이 된 지 2주가 지났다. 0서클 첫 과제로 받게된 C언어 라이브러리를 구현하는 과제를 2주간 수행하였다. 라피신 때보다 급박하지 않아서 여유롭게 할 수 있었다.
현재 코드들을 예외처리도 다 끝내고, 테스트가 잘 돌아가게 끔 완성한 상태이다. 일단 내가 공부한 내용을 정리하는게 동료평가 때 설명하기도 좋고 복습에도 효율적이라 블로그에 정리하기로 했다.
먼저, mem 관련 함수 먼저 정리하겠다
사실, 다른 함수들을 구현하는 것은 라피신 때의 내용과 겹치는 것들이 많아 괜찮았지만, mem 관련 함수는 생소해서 공부할 것이 많았던 것 같다.
참고로, 내가 정의한 libft.h 헤더에는 <unistd.h>와 <stdlib.h>가 include 되어있다. 따라서 libft.h를 호출하면, 따로 정의하지 않고도 <unistd.h> 에 정의된 size_t 타입과 <stdlib.h>의 malloc/free를 사용할 수 있다.
(1) memset : 메모리의 내용(값)을 원하는 크기만큼 특정 값으로 설정하는 함수
- memory + setting
- 어떤 배열 등을 특정 값으로 모두 초기화 할 때 유용하다
- 매뉴얼(영문번역) :
이름 : memset –- byte string을 바이트 값으로 채운다
라이브러리 : 표준 C 라이브러리 (libc, -lc)
시놉시스 :
#include <string.h>
void *memset(void *b, int c, size_t len);
설명 : memset() 함수는 (unsigned char 형으로 변환된) 값 c를 string b에 len 바이트만큼 채운다
리턴값 : memset() 함수는 그것의 첫번째 argument(매개변수)를 리턴한다
- b라는 바이트 배열에 c라는 값을 채운다.
- (void *) 형식으로 값을 받는 이유 ?
: (void *) 형식으로 프로토타입을 선언하면, int 형이던 char 형이던, 그 외에 어떤 타입이던 포인터 배열을 매개변수로 받을 수 있다.
: 예를 들어, (char *) 형으로 매개변수 형식을 지정하면, (int *) 타입의 int형 포인터 배열은 값으로 받지 못하게 된다.
- (void *)형의 매개변수를 (unsigned char *)형으로 캐스팅해서 연산을 수행한 이유?
: 메모리 주솟값, 하드웨어 제어를 위한 비트조작, 바이트 데이터 처리 등에서는 unsigned char를 사용하는 것이 기본이다. 메모리 주솟값에는 부호가 없고, 바이트 데이터 처리도 마찬가지다. 이러한 관례를 따르는 게 좋다. 또 unsigned char 은 메모리를 8비트, 즉 1바이트씩 끊어서 접근한다.
만일, 메모리 주솟값을 부호가 있는 값으로 처리하면 많은 문제가 생길 수 있다. 부호, 비부호, 무엇을 쓰든 비트 패턴 자체는 동일하지만, 값을 해석하는 방식이 다르기 때문에 부호 있는 값으로 처리하면 프로그램 중단이 발생할 것이다.
- (void) 포인터로 연산하면 안되는 이유?
: 음수를 저장할 때, 2의 보수 형태로 저장하게 된다. 단순히 부호 여부가 아니라 데이터를 저장하는 방식이 달라진다. 따라서 비부호인 unsigned char 형식으로 캐스팅할 경우가제일 안전하다. 부호 여부는 비트 연산에서 심각하게 다른 차이를 만들기 때문이다.
ex)
10000000 >> 1 = 01000000 (128 / 2 = 64)
10000000 >> 1 = 11000000 (-128 / 2 = -64)
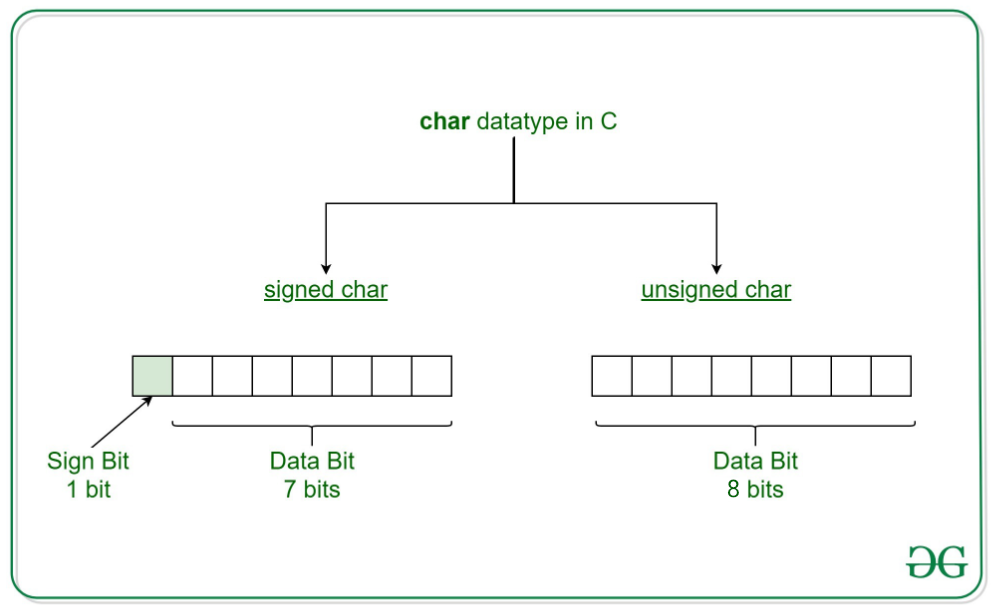
- (unsigned char) 타입이란?
: char 타입은 단일 문자나 단일 바이트의 메모리를 저장하는 데 사용된다.
이때, unsigned char은 8비트의 메모리를 부호 비트 없이 모두 차지한다. 따라서 unsigned char 의 범위는 0 ~ 255가 된다. signed char 의 경우는 첫번째 비트를 부호 비트로 사용하므로 data를 저장할 수 있는 공간은 7비트 밖에 되지 않는다. 이때, signed char 의 범위는 -127 ~ 128 이다. (이런한 이유에서, 256개의 문자를 표현할 수 있는 확장아스키코드의 경우에는 unsigned char 형을 써야한다.)
- 구현 코드 예시 :
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
#include "libft.h"
void *ft_memset(void *b, int c, size_t len)
{
size_t i;
unsigned char *tmp;
tmp = b;
i = 0;
while (i < len)
{
tmp[i] = (unsigned char)c;
i++;
}
return (b);
}
|
cs |
- size_t 형인 len과 비교하며 인덱스 변수인 i 를 증가시키기 때문에 i의 타입도 size_t 형으로 맞춰주었다
- (unsigned char *)타입의 포인터 배열인 tmp 에 c의 값을 할당할 때, c도 unsigned char로 캐스팅하여 할당해 주었다.
- 참고) size_t 란 무슨 타입인가? (주의 ! 엄밀히 unsigned int 타입이 아니다)
size_t는 '이론상 가장 큰 사이즈를 담을 수 있는 unsigned 데이터 타입'으로 정의된다. 즉, 32비트 머신에서는 32비트 사이즈의 unsigned 정수형(int가 아니라 그냥 '정수'를 의미함), 64비트 머신에서는 64비트 사이즈의 unsigned 정수형(unsigned long long)이다. 향후 등장할 지도 모르는 128비트 머신이라던가 더 큰 머신이 존재한다면 그에 따라 더 큰 사이즈가 될 것이다.
따라서 unsigned int로 착각하고 int나 unsigned int로 형변환을 해서 사용하다가 범위가 벗어나는 버그가 발생할 가능성이 있으니 유의해두는 게 좋다. 특히 큰 데이터나 큰 용량을 가진 파일을 처리할 때 주의해야할 것이다.
- 참고) memset 사용시 주의할 점
memset은 메모리 블록을 채운다. 이 때 메모리 블록을 채우는 기준은 1byte(8bit) 이기 때문에, 0이 아닌 다른 값으로 메모리를 초기화하고자할 때 문제가 발생할 수 있다.
예를 들어, 위 배열을 1로 채우기 위해서 memset(array, 1, sizeof(array)) 를 사용하게 되면 unsigned char는 1바이트, int는 4바이트이기 때문에 다음과 같이 채워질 것이다.
arr pointer | 0x00000001 | 0x0000001 | 0x000001 | ... // 사용자가 기대한 메모리 초기화 ----------------------------------- 0x01010101 | 0x01010101 | 0x01010101 | ... // memset이 수행한 메모리 결과
결과적으로, array 배열은 다른 값으로 채워지게 된다. 만약 array 배열이 char 또는 unsigned char형이었다면, 올바른 값이 들어가게 된다.
또한, memset의 2번째 인자는 내부적으로 unsigned char로 해석된다고 언급되어있다. 따라서 2번째 인자를 255보다 큰 값을 집어넣게 되면 제대로된 초기화가 수행될 수 없다. 만약, 257(0x0101)로 값을 초기화하려고 한다면, 255 이상의 값은 무시되고 1(0x0001)로 초기화되게 된다.
또, 바이트(8비트 = unsigned char 크기) 단위로 초기화를 하는 만큼, int형 배열이나 long long형 배열과 같은 경우, 배열에 memset함수로 0, -1은 넣을 수 있는데, 2, 3과 같은 건 넣을 수 없다.
(2) bzero : 바이트 스트링을 0으로 채운다
- memset과 bzero는 공통적으로, 어떤 배열(공간)을 특정 값으로 '초기화'하는 데 이용되는 함수라 할 수 있다.
- memset은 bzero와 다르게, 0이외의 다른 값을 채울 수 있고, "byte"단위로 값을 채운다는 데에서 차이가 있다.
- 반면, bzero는 해당 메모리 공간에 0만 채울 수 있다.
- 또한 memset은, 아무것도 리턴하지 않는 bzero와 다르게, 메모리 block의 주소를 반환한다.
- 매뉴얼(영문번역) :
이름 : bzero -- byte string을 0으로 채운다
라이브러리 : 표준 C 라이브러리 (libc, -lc)
시놉시스 :
#include <string.h>
void bzero(void *s, size_t n);
설명 : bzero() 함수는 string s에 n개의 0인 바이트들을 채운다.
n이 0일 경우, bzero()는 아무것도 수행하지 않는다.
- 구현 코드 예시 :
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
#include "libft.h"
void ft_bzero(void *s, size_t n)
{
size_t i;
unsigned char *p;
p = s;
i = 0;
while (i < n)
{
p[i] = 0;
i++;
}
}
|
cs |
- (void *)형 바이트 스트링을 unsigned char로 형변환하여, n개의 바이트에 0을 채워 초기화하였다.
(3) memcpy : 메모리 복사 함수
- 메모리를 n 바이트 만큼 복사한다
- memory + copy
- 매뉴얼(영문번역) :
이름 : memcpy -- 메모리 데이터를 복사한다
라이브러리 : 표준 C 라이브러리 (libc, -lc)
시놉시스 :
#include <string.h>
void *memcpy(void *restrict dst, const void *restrict src, size_t n);
설명 : memcpy()함수는 메모리 영역 src에서 메모리 영역 dst로 n개의 바이트를 복사한다.
src와 dst의 메모리 영역이 겹칠 경우의 동작은 정의되지 않는다.
dst와 src가 겹칠 경우에 적용하려면, 이 함수 대신에 memmove 함수를 대신 쓰기를 권장한다.
리턴값 : memcpy() 함수는 dst의 원래 값을 리턴한다
- "src와 dst의 메모리 영역이 겹칠 경우의 동작은 정의되지 않는다" 의 의미?
만일 char s[10] = "Hello-World"를 선언했다고 가정하자. 이때 memcpy(s, s+ 5);를 실행할 경우, 복사하고자 하는 메모리 영역이 겹쳐, 해당 영역에 값을 읽음과 동시에 값을 수정하게 된다. 원본의 값이 아닌, 다르게 수정된 값을 dst에 복사하게 될 위험이 있다. 즉, 이런 상황에서 원본의 값을 제대로 복사하기 위한 동작이 따로 정의 되지 않았다는 뜻이다.
- 구현 코드 예시 :
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
#include "libft.h"
void *ft_memcpy(void *dst, const void *src, size_t n)
{
size_t i;
unsigned char *pdst;
unsigned char *psrc;
if (src == dst)
return (dst);
pdst = (unsigned char *)dst;
psrc = (unsigned char *)src;
i = 0;
while (i < n)
{
pdst[i] = psrc[i];
i++;
}
return (dst);
}
|
cs |
- dst와 src가 둘다 NULL일 경우, dst(NULL)을 리턴한다.
이유 : 둘중 하나라도 null이면 주소가 0인 메모리를 참조할 수 없어서 segfault가 발생한다. 또한 dst가 null이기 때문에 null을 리턴한다. 이때, null이 src와 dst 중 하나만 들어오면 seg fault가 반환되는 게 올바른 값이며, null이 2개 들어오면 null을 반환한다. 그래서 if문에서 || 이 아닌, &&를 사용하였다.
만일, 이때 위에서 if문으로 처리를 하지 않고 while 문이 돌게 되면 segfault가 난다.
dst == src 일 때 dst가 반환하도록 예외처리를 해줘도 같은 결과가 된다. 또한, 주소만 같다면 굳이 복사하지 않고 dst를 반환해주는게 성능상 더 빠르고 효율적이기도 하다.
- 프로토타입에 선언된 restrict형은 구현에 사용하지 않았다.
- restrict 타입이란? (매뉴얼의 프로토타입에 선언된 매개변수의 자료형)
최적화 키워드 중의 하나.
restrict 를 쓰면, 그 포인터가 가르키는 객체는 다른 포인터가 가르키지 않는다는 것을 나타낸다
restrict를 사용할 시, 내부적으로 같은 메모리 공간을 가리키는지, 메모리가 겹치는지 모두 확인을 할 필요가 없어지기 때문에, 성능이 더 높아진다.
(4) memccpy : 메모리 복사함수2 (memcpy와 차이 있음)
- 메모리 데이터를 복사하다가, 특정 문자가 발견되면 복사를 중단한다. 그리고 해당 위치의 다음 dst 주소를 리턴한다.
- 매뉴얼(영문번역) :
이름 : memccpy -- 메모리 데이터를 특정 문자가 발견될 때 까지 복사한다
라이브러리 : 표준 C 라이브러리 (libc, -lc)
시놉시스 :
#include <string.h>
void *memccpy(void *restrict dst, const void *restrict src, int c, size_t n);
설명 : memccpy()함수는 string src에서 string dst로 바이트들을 복사한다.
만일 (unsigned char 형으로 변환된) 문자 c가 문자열 src에서 발견되면, 복사가 중단된다.
그리고 c가 발견된 위치 다음의 byte의 dst 포인터 주소가 리턴된다.
그렇지 않으면, n 바이트가 복사되며 null 포인터가 반환된다.
src와 dst의 메모리 영역이 겹칠 경우의 동작은 정의되지 않는다.
- 구현 코드 예시 :
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
#include "libft.h"
void *ft_memccpy(void *dst, const void *src, int c, size_t n)
{
size_t i;
unsigned char *pd;
unsigned char *ps;
pd = (unsigned char *)dst;
ps = (unsigned char *)src;
i = 0;
while (i < n)
{
pd[i] = ps[i];
if (ps[i] == (unsigned char)c)
return (dst + i + 1);
i++;
}
return (0);
}
|
cs |
- unsigned char 형으로 변환된 문자 c가 src에서 발견될 경우, 복사가 중단된다. 그리고 해당 위치 다음의 dst의 포인터를 리턴한다.
(5) memmove : 메모리 복사함수3 (memcpy와 중요한 차이 있음)
- memory + move
- 실질적인 동작은 메모리의 이동이 아닌 메모리의 복사
- 매뉴얼(영문번역) :
이름 : memmove -- byte string을 복사한다
라이브러리 : 표준 C 라이브러리 (libc, -lc)
시놉시스 :
#include <string.h>
void *memmove(void *dst, const void *src, size_t len);
설명 : memmove()함수는 string src에서 string dst로 len만큼의 바이트들을 복사한다.
2개의 string의 메모리 영역은 겹칠 수 있다;
그렇지만 복사는 항상 비파괴적인 방식으로 이루어진다
리턴값 : memmove() 함수는 dst의 원래 값을 리턴한다
- memcpy와의 중요한 차이점!!!
메모리 영역이 중첩될 수 있는 객체 간 복사를 허용한다.
예를 들어, char str[] = "Hello-world"이고, memcpy(str, str + 3)을 실행해서 메모리 영역이 겹치는 경우를 가정하자.
이런 경우에는 원본 문자열(src)의 수정과 복사가 동시에 이루어지기 때문에 부정확한 값이 복사될 위험이 있다. 그러나 이때 memmove함수는 이러한 위험이 없다. 임시 버퍼에 src의 문자열을 우선 저장한 뒤, 저장된 값을 dst에 다시 붙여넣어 원본 값의 손상 없이 dst에 붙여넣는다. 그렇기 때문에 memcpy보다 속도가 떨어지나 더 안전하다.
다른 방식으론, 문자열의 주솟값을 비교하여 복사하는 방법이 있다. dst의 주소가 sr보다 뒤에 있는 경우(dst > src 인 경우), src의 뒷부분부터 dst의 뒷부분에 한칸씩 복사하며 앞으로 이동할 수 있다. 그렇지 않고 dst의 주소가 src보다 앞에 있는 경우(dst < src), 앞에서부터 복사를 수행한다.
- 구현 코드 예시 :
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
#include "libft.h"
void *ft_memmove(void *dst, const void *src, size_t len)
{
unsigned char *psrc;
unsigned char *pdst;
psrc = (unsigned char *)src;
pdst = (unsigned char *)dst;
if (src == dst)
return (dst);
else if (src > dst)
{
while (len--)
*(pdst++) = *(psrc++);
}
else
{
psrc += len - 1;
pdst += len - 1;
while (len--)
*(pdst--) = *(psrc--);
}
return (dst);
}
|
cs |
- src와 dst가 같을 경우에는, dst의 문자열이 이미 src와 같은 것이므로, 복사를 수행하지 않고 바로 dst를 리턴한다
- overlapping 을 처리하기 위해, dst의 주소가 sr보다 뒤에 있는 경우(dst > src 인 경우), src의 끝부분부터 복사한다. 그렇지 않고 dst의 주소가 src보다 앞에 있는 경우(dst < src), 앞에서부터 복사를 수행한다.
- overlapping 을 처리하는 방식을 이해하기 쉬운 시각 자료
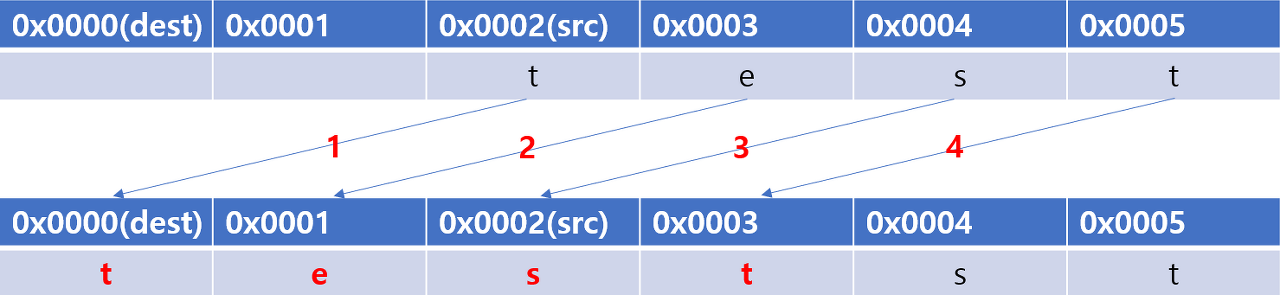
1. src의 첫번째 byte부터 순차적으로 dest에 한 btye씩 복사하게 되는 경우
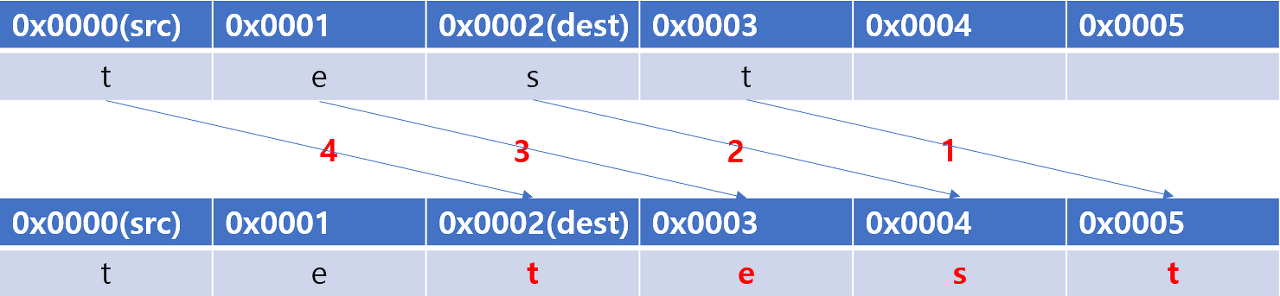
2. src의 마지막 byte부터 한 btye씩 순차적으로 dest에 복사하는 경우
이미지 출처 : https://hand-over.tistory.com/47
memmove 사용법 및 구현 - C 메모리 이동
사용법 #include void *memmove(void *dest, const void *src, size_t n); 정의 memmove() 함수는 src 메모리 영역에서 dest 메모리 영역으로 n byte 만큼 복사합니다. src 배열은 src와 dest 의 메모리 영역과 겹..
hand-over.tistory.com
(6) memchr : 메모리 속 문자 찾는 함수
- 메모리 블록에서의 문자를 찾는다.
- s가 가리키는 메모리의 처음 n 바이트 중에서 처음으로 c와 일치하는 값의 주소를 리턴한다.
- 매뉴얼(영문번역) :
이름 : memchr -- byte string 내의 byte의 위치를 찾는다
라이브러리 : 표준 C 라이브러리 (libc, -lc)
시놉시스 :
#include <string.h>
void *memchr(const void *s, int c, size_t n);
설명 : memchr() 함수는 string s 속에서 (unsigned char형으로 변환된) c가 처음 발견되는 위치를 찾는다
리턴값 : memchr() 함수는 c를 찾아낸 해당 바이트가 위치한 곳의 포인터를 반환한다.
만약 n개의 바이트 중에서 해당 바이트를 찾을 수 없다면, null을 반환한다.
- 구현 코드 예시 :
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
#include "libft.h"
void *ft_memchr(const void *s, int c, size_t n)
{
size_t i;
unsigned char *p;
p = (unsigned char *)s;
i = 0;
while (i < n)
{
if (p[i] == (unsigned char)c)
return ((void *)(p + i));
i++;
}
return (0);
}
|
cs |
- 바이트 단위의 메모리 접근을 위해 (unsigned char *)형으로 변환한 포인터를, 다시 (void *)형으로 형변환 해준 뒤 리턴하였다.
(7) memcmp : 메모리 비교 함수
- 두 개의 메모리 블록을 비교한다
- 메모리 블록의 데이터를 n 만큼 비교하여, 같다면 0 리턴. 다르다면 0이 아닌 값을 리턴
- 매뉴얼(영문번역) :
이름 : memcmp -- byte string을 비교한다
라이브러리 : 표준 C 라이브러리 (libc, -lc)
시놉시스 :
#include <string.h>
int memcmp(const void *s1, const void *s2, size_t n);
설명 : memcmp() 함수는 byte string s1을 byte string s2와 비교한다.
2개의 string들은 모두 n 바이트 길이라고 가정한다.
리턴값 : memcmp() 함수는 두개의 문자열(string)이 동일할 경우 0을 리턴한다.
그렇지 않으면, 처음으로 일치하지 않는 부분의 바이트들의 차이값을 리턴한다.
(unsigned char의 값으로 취급되므로, 예를 들어, '\200'은 '\0'보다 더 크다)
길이가 0인 문자열들 또한 동일한 문자열로 취급된다.
이 동작은 C에 요구되지 않으며, portable 코드가 오직 리턴값의 부호에 의해서만 결정되야한다.
- unsigned char 값으로 비교된다는 것을 주의!
- 구현 코드 예시 :
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
#include "libft.h"
int ft_memcmp(const void *s1, const void *s2, size_t n)
{
size_t i;
unsigned char *ptr1;
unsigned char *ptr2;
ptr1 = (unsigned char *)s1;
ptr2 = (unsigned char *)s2;
i = 0;
while (i < n)
{
if (ptr1[i] != ptr2[i])
return ((int)(ptr1[i] - ptr2[i]));
i++;
}
return (0);
}
|
- 길이가 0인 문자열일 경우에는 동일한 것으로 취급되므로 0을 리턴한다.
- 두 문자열이 다를 경우, 다르게 나온 첫번째 바이트의 값 차이를 리턴한다.
이때, unsigned char 형의 차이값을 int형으로 캐스팅하여 리턴해주었다.
참고자료 출처:
https://dojang.io/mod/forum/discuss.php?d=1459
C 언어 코딩 도장: void 포인터 연산시 왜 unsigned char포인터를 써야하나요?
"void 포인터 연산은 호환성을 위해 사용하지 않는 것이 좋습니다. 즉, 표준을 지켜야 호환성이 좋은 코드가 됩니다. 만약 메모리를 1바이트씩 접근하려면 unsigned char *를 사용하면 됩니다." https:/
dojang.io
https://www.geeksforgeeks.org/unsigned-char-in-c-with-examples/
unsigned char in C with Examples - GeeksforGeeks
A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions.
www.geeksforgeeks.org
https://yaaam.tistory.com/entry/CC-bzero-%EC%99%80-memset%EC%9D%98-%EC%B0%A8%EC%9D%B4%EC%A0%90
[C/C++] bzero 와 memset의 차이점
1. bezro #include void bzero(void *s, size_t n); 이름에서도 알 수 있듯이 'zero' 값을 채움 0x00의 값을 s 영역에 n 크기만큼 초기화 -> 다른 값은 사용 불가능 deprecated된 함수. 실제로 'man bzero'를 실행..
yaaam.tistory.com
memset 사용시 주의할 점
C 또는 C++ 언어에서, 구조체 또는 배열을 초기화할 때 memset 함수를 사용하는 것을 종종 볼 수 있습니다. #ifdef CPP // C++에서는 cstring 헤더를 사용합니다(string.h 를 사용해도 됩니다) #include #elif #in..
minusi.tistory.com
c언어 memset : 어떠한 수들만 초기화 가능할까?
memset 함수는 시작 주소값부터 sz 바이트만큼, 바이트 단위로 초기화를 해 주는 함수입니다. 보통 2번째 인자에 넣는 값이 0, -1인 경우가 상당히 많은데요. 0x3f나 0x7f 등도 ps에는 꽤 많이 쓰입니
codingdog.tistory.com
https://karupro.tistory.com/17
[C99] 포인터 최적화를 위한 restrict 키워드
이 키워드가 추가됨에 따라 , 에서도 알 수 있듯 대부분의 표준 라이브러리 함수들에 restrict가 붙었습니다. 최적화 키워드 중 하나인데, restrict을 쓰면 그 포인터가 가르키는 객체는 다른 포인
karupro.tistory.com
https://hand-over.tistory.com/47
memmove 사용법 및 구현 - C 메모리 이동
사용법 #include void *memmove(void *dest, const void *src, size_t n); 정의 memmove() 함수는 src 메모리 영역에서 dest 메모리 영역으로 n byte 만큼 복사합니다. src 배열은 src와 dest 의 메모리 영역과 겹..
hand-over.tistory.com
'IT > 42Seoul' 카테고리의 다른 글
| [Libft] C 언어 라이브러리 구현_Part2_추가함수 구현2 (0) | 2021.05.23 |
|---|---|
| [Libft] C 언어 라이브러리 구현_Part2_추가함수 구현1 (0) | 2021.05.23 |
| [Libft] C 언어 라이브러리 구현_Part1_malloc을 사용한 함수 (0) | 2021.05.20 |
| [Libft] C 언어 라이브러리 구현_Part1_문자 판별 + 변환 관련 함수 (0) | 2021.05.20 |
| [Libft] C 언어 라이브러리 구현_Part1_문자열 관련 함수 (0) | 2021.05.20 |