![[컴파일러] LL 파서와 LR 파서](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fb87sfx%2FbtrEt3Lc8E7%2FsuILOomomHlHGTQHeYdW4k%2Fimg.png)
안녕하세요 밥한그릇 입니다.
제가 이번에 학교에서 수강한 컴파일러 과목의 기말고사 시험이 끝난 지 이틀이 지났네요.. 시간을 많이 들여 강의노트를 정리한 페이지를 만들고, 거의 통째로 외우다시피 시험 준비를 했어요.
그렇지만 불행하게도 강의노트에 잘 적혀있지 않은 부분들에서 기말 고사 문제가 많이 나와서 슬펐습니다. (ㅠㅠ)
제가 강의노트의 어려운 예제들을 풀고 이해하는 데 들었던 시간이 상당했었거든요. 인터넷에도 친절히 설명하는 자료가 거의 없었어서 더욱 그랬죠. 그래서 "예제를 이해하고 공부한 내 노력이 아까우니, 따로 예제들을 쉽게 풀이하는 포스팅을 만들어보자!"는 생각이 들었습니다.
아무래도 과목 진도 상 중후반쯤에 위치한 내용에다가 그 분량이 많아요. 그러니 컴파일러 과목의 앞부분에 대한 기초 설명은 다소 생략할 수 있습니다. 사전 지식이 어느정도 있다는 가정 하에 설명할 예정입니다.
그럼 시작합니다. ^^
예제 문제를 풀기 전 개념 빌드업 포스팅으로 시작합니다.
컴파일러와 parser?
우선 컴파일러가 무엇인지부터 간단히 설명하겠습니다. 컴파일러는 우리가 흔히 아는 컴파일러 그대로입니다.
즉, 코드를 실행시킨 뒤, 그 실행 결과를 돌려주는 프로그램입니다.
기본적으로 컴파일러 과정은 lexer -> parser -> type-checker -> interpreter의 과정으로 이루어지게 됩니다.
lexer는 토큰이라는 단위로 코드의 문법 오류를 검출하는 역할을 합니다.
예를 들어, i + 2 = 3 이라는 문장이 있다고 해봅시다.
이때, 매 문장 끝에 ;(semicolon)라는 토큰을 붙여야한다는 문법 규칙이 있을 경우, ";" 라는 토큰을 붙이지 않은 이 구문을 문법 오류로 처리해준다는 뜻입니다.
parser는 프로그래밍 코드를 입력 받은 뒤, 그걸 프로그램이 해석할 수 있는 단위로 쪼개 그 문장을 구조를 알아내는 구문 분석 작업을 해주는 프로그램입니다.
i = i + 1 이걸 int i (int 변수), = (할당 연산자), i(int 변수), +(수학 연산자),1(1이라는 정수형 숫자) 이런 식으로 구조를 쪼개 준다는 것이죠.
type checker는 주어진 구문에 타입 오류가 없는 지 검사합니다. 만약 float i; 로 앞서 선언한 변수에, 타입캐스팅 연산자 등이 없이 바로 i = 'a' 라는 식으로 char 값이 들어간다면? float 변수에 char 값을 담으려는 충돌이 일어나므로 타입 오류로 분류해야겠습니다.
interpreter는 앞선 과정을 통해 코드를 검사해봤을 때 아무 문제가 없는 경우 최종적으로 실행되는 데요.
이 코드를 실행해 나오는 결과를 보여줍니다.
컴파일러 실행 하는 중에, 입력된 코드의 오류를 발견하게 되면 어떻게 될까요?
그 과정에서 나오는 모든 오류를 보여준 후 다음 과정으로 넘어가지 않고 종료됩니다.
Parser의 원리
우선, 프로그래밍 언어를 유도하는 과정에 대해 먼저 설명해볼까요.
프로그래밍 언어, 즉 코드는, 쉽게 말하면, 어떤 규칙에 따라 문자열을 확장한 것에 불과하다고 볼 수 있습니다.

저기 트리 루트에 있는 expr 보이시나요? 우리가 expr이라는 것만 갖고 있는 상태라고 해봅시다.
그리고 우리는 다음 epxr 과 연산자, term이 필요하다는 규칙도 가지고 있다고 해봅시다.
그럼 저런 방식으로 expr을 expr + term이라는 문자열로 확장시킬 수 있는 거에요. 다양한 문법 규칙을 통해 문자열을 확장하면, 저 코드가 아니더라도 우리가 원하는 문법 구조 안의 모든 프로그래밍 코드를 표현할 수 있습니다.
program이라는 토큰 하나에서 시작해서 int main() {int i; i = 0; i = i + 1; }이런 식으로 얼마든지 확장이 가능해지거든요.
이렇게 문법 규칙에 따라 문자열을 유도하는 과정을 거꾸로 생각하면, 파싱이 가능합니다.
주어진 문법규칙을 통해, 이 코드가 문법 규칙에 맞는 지 체크하고 코드를 parsing 할 수 있거든요.
만일 어떤 변수가 나왔고 그 다음에 "="라는 연산자가 나왔다. 그러면 그 우변에 무조건 숫자 혹은 숫자를 사칙연산한 식이 나와야한다는 규칙이 있다고 가정합시다. 그러면 문법 규칙은 "변수 = 식", "식 = 숫자를 사칙연산한 식 또는 그냥 숫자" 이렇게 나타낼 수 있겠죠.
이런 상황에서, 입력으로 변수 i = 'c' + 9라는 문장이 들어와 이걸 파싱한다고 합시다.
이 규칙에 따르려면 변수(=i), 할당연산자("=") 뒤에 나오는 건 반드시 숫자계산식이여야 해요. 그런데 그 뒤의 'c'+9라는 식은 숫자로만 사칙연산된 식도 아니고 숫자 그 자체인 것도 아니죠. 이때 이걸 발견해서 parsing 에러를 내게 되는 거에요.
파서 입장에서는 "변수랑 "=" 라는 연산자를 읽었으니, 변수 = 숫자식 으로 해석해야한다! 그러니 뒤에 숫자식이 나오는 지 체크해보자!"하고 체크해보니 아니라 이거죠.
만일 i = 1 + 1 과 같이 앞선 문법 규칙을 만족하는 식이면 parsing 에러 없이 돌아가는 것이구요.
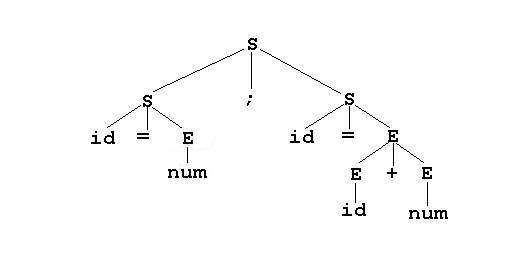
parsing 에러 없이 파서가 잘 돌아가면 어떻게 될까요?
오류 없이 잘 parsing 이 끝나면, parser tree를 결과물로 만들게 됩니다. 문장구조를 분석한 그 요소들을 이렇게 배치해 일종의 tree 모양으로 확장 시키는 모습이죠.
파서를 설명할 때 non-terminal과 terminal에 대한 설명이 계속 나오게 되는데요. 이걸 확실하게 짚고 넘어갑시다.
여기에서 첫번째 트리를 봅시다.
여기서 최종상태 (말단노드)인 id, =, num 등을 terminal 문자, 최종상태가 아닌 S, E 등을 non-terminal이라고 할거에요.
이 부분은 parsing 테이블을 볼 때 계속해서 언급이 나오니, 헷갈리지 않게 꼭 기억해두어야합니다. non-terminal이 확장되면 최종상태인 terminal로 변하는 것이므로, non-terminal -> terminal의 구조라고 생각해두시면 좋아요.
Parser의 종류
앞서 parser는 프로그램코드를 특정한 의미를 가진 구문으로 쪼갠다고 말씀드렸습니다.
그러한 parser에도 LL 파서(top-down parser)와 LR 파서(bottom-up parser)의 2가지 종류가 있는데요.
초기상태에서 말단 요소로 확장하는 방식이 LL 파서에 똑같이 적용됩니다. 그래서 top-down이라고 부르게 되지요.
LL 파서는 이렇게 쪼개기 위해서 Left-most derivation 순으로 분석합니다. 왼쪽에다가 문자를 새로 붙여가면서 확장하는 거에요.
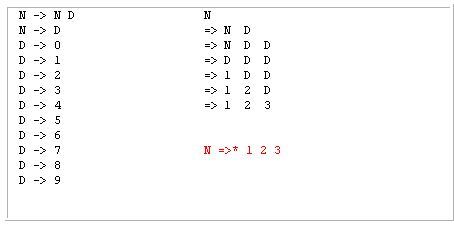
다음과 같이 왼쪽부터 그 요소가 추가되거나 바뀌고 있죠. 왼쪽부터 유도한다하여 left-most derivation입니다.
LL 파서도 그 종류가 2가지로 나뉘는데요, deterministic과 non-deterministic입니다. non-deterministic은 predictive(예측 가능) parser라고도 불려요.
어떤 상태(non-termial=최종상태가 아닌 것)가 주어졌을 때, 이를 최종 상태(=입력값=terminal)로 확장시키는 데 사용할 수 있는 규칙이 여러 개냐 아니냐로 구분됩니다.
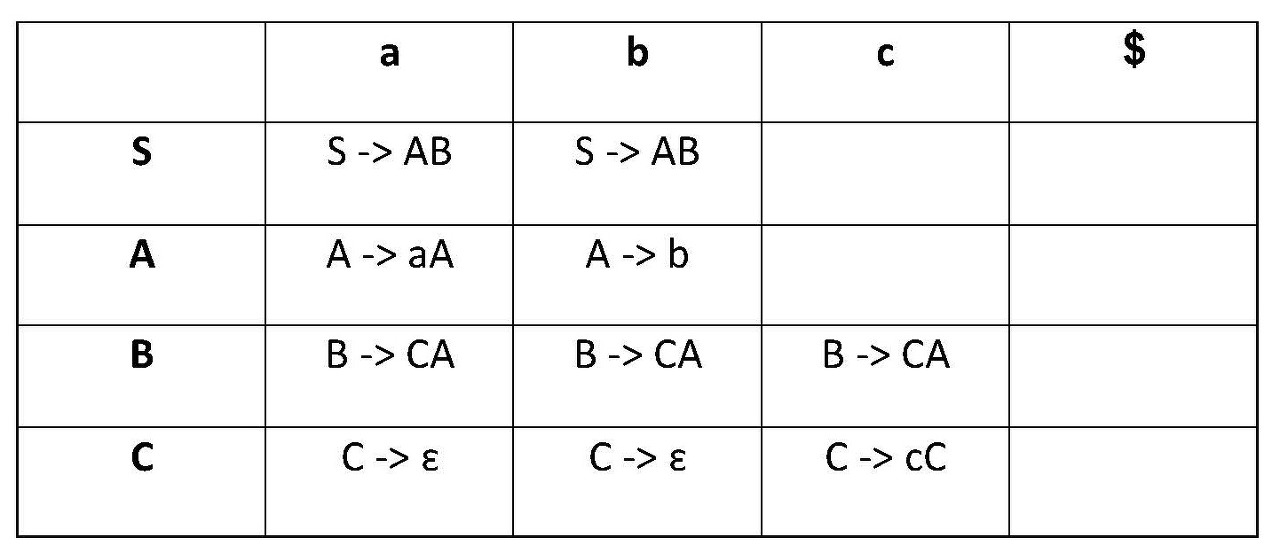
LL 파서는 문법 규칙과 그 언어의 정규식을 통해 만들어진 parsing table을 사용하여 parsing 합니다.
아래의 표는 LL(1)의 parsing table이라고 볼 수 있습니다. 각 칸에 문법 규칙이 하나씩 들어있으니까 LL 파서 중 predictive parser라고 볼 수 있겠네요. 만일 어떤 non-terminal과 termianal에 대해 확장 규칙이 여러 개면 여러 가지의 경우가 발생할 수 있으므로 backtracking이 일어나게 된다고 합니다.
이 parsing table은 "현재 상태는 S인 non-terminal인데, 현재 읽은 Input 값이 a라면? S->AB라는 규칙을 적용하세요~" 라는 의미를 담고 있는 parsing table이랍니다. 자세한 것은 예제 풀이 포스팅에서 보게 될 거에요.

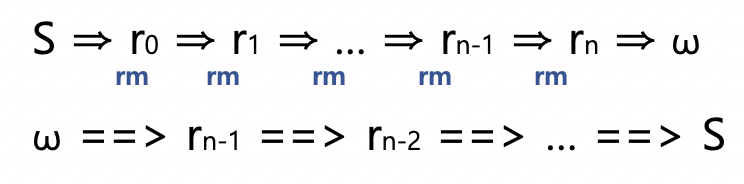
LR 파서는 마찬가지로 parsing 테이블을 만들지만, right-most derivation의 역순으로 파싱을 수행합니다.
문자열을 확장시키는 유도과정을 뒤짚어 점점 초기상태로 돌리는 방향으로 Parsing을 하는 것이죠.
그래서 트리의 말단에서 위로 올라가는 방향으로 보여 bottom-up parsing이라고도 부릅니다.
LR parsing table은 ACTION 테이블과 GOTO 테이블이 합쳐진 형태에요.
먼저, Action 테이블에서는 어떤 상태(states)에서 입력값(terminals) 받았을 때 무슨 action을 취하는 지 알려줍니다.
그리고 Goto 테이블에서는 어떤 상태(states)에서 입력값이 아닌 상태(Non-terminals) 받았을 때 다음 상태를 알려주지요.
LR 파서의 기본 동작들(actions)는 다음과 같아요. shift, reduce, accept, error의 4가지 입니다.
그 기본 동작들의 의미는 다음과 같으며, 이들을 활용해 최종상태(input)에서 초기 상태로 쭉쭉 돌릴 수 있게 되는 것입니다.
- shift : input symbol을 스택에 push (그 위에 상태 n을 저장)
- accept : parsing 끝남
- error : syntax에 오류
- reduce : handle을 non-terminal로 치환.
일단 이렇게 매우 간략히 LL 파서와 LR 파서의 개념에 대해 정리해보았습니다.
예제 풀이를 위한 빌드업 포스팅이다보니 좀 짧게 진행하게 되었네요.
질문이나 추가 설명 요청, 또는 지적은 댓글로 남겨주세요!
감사합니다.
'IT > 학과 공부' 카테고리의 다른 글
| [컴파일러] LR 파서 문제 풀이 (0) | 2022.06.11 |
|---|---|
| [컴파일러] LL(1) 파서 문제 풀이 (0) | 2022.06.11 |
| C에서 시그널을 보내고 처리하는 방법 (kill, signal, sigaction) (0) | 2022.01.06 |
| [KOCW] 운영체제 3차시 - 프로세스 관리 (0) | 2021.11.08 |
| [KOCW] 운영체제 3차시 - 운영체제 서비스 (0) | 2021.11.08 |